你真的不了解这个星球—涨姿势的大数据
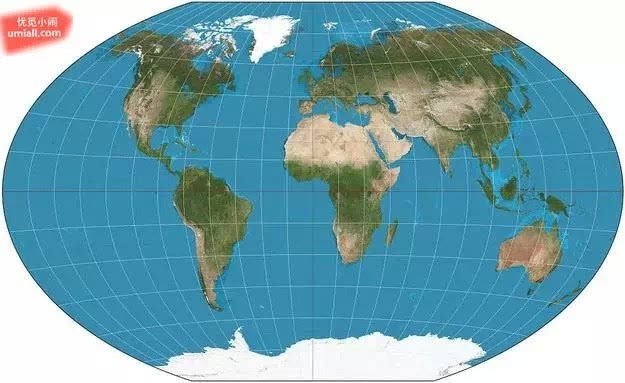
1. 首先来看看地球,看起来不错哟,地球~
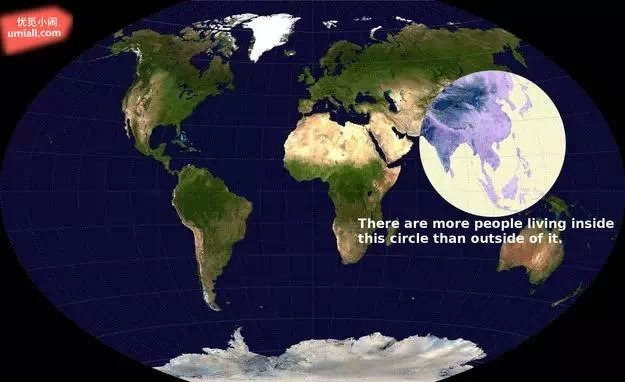
2. 图中圈圈里头的人口,比其他地区的所有总和都还要多。
3. 以整个地球史来看,曾活过的人类高达1150亿人,其中包括现存的70亿人口,你也是其中的一员。
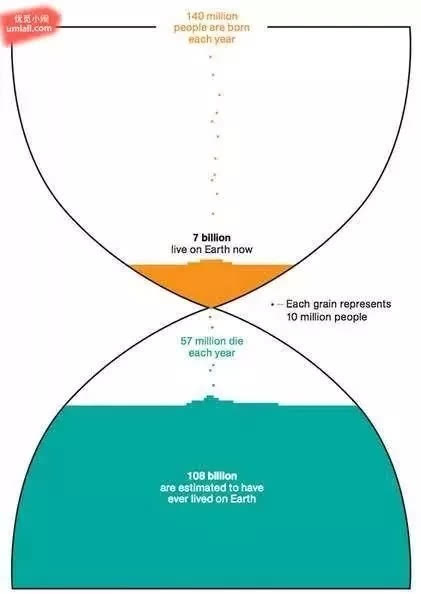
上图每一个点就是1000万人,每年有1.4亿人诞生,现在有70亿人口;每年有5700万人死亡,估计曾有1080亿人在地球生活过,然后死去。
4. 每一天,地球都有人飞来又飞去,就像下图这样:
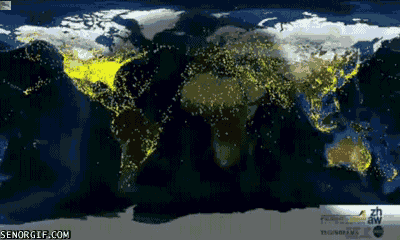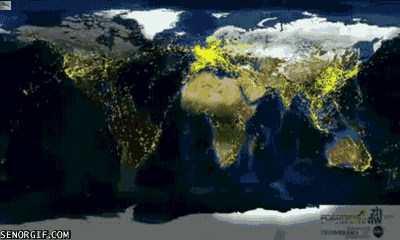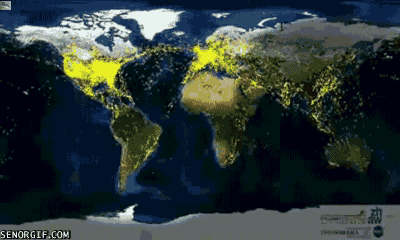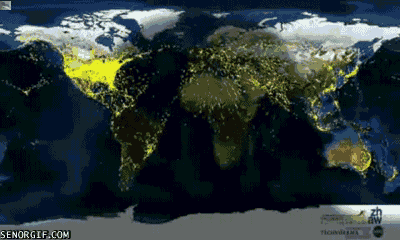
5. 这是南极州,比美国还要大呢!
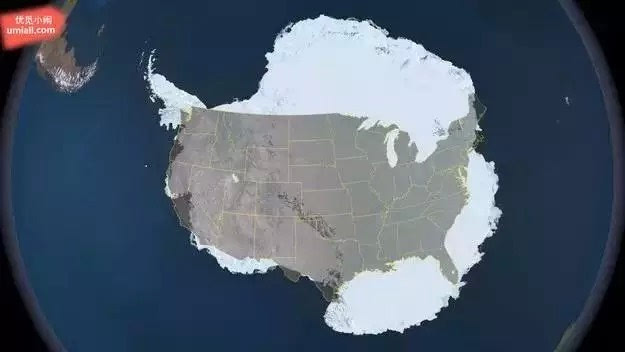
还有,非洲比你想像的还要大多了,看看一些国家塞进来的样子…
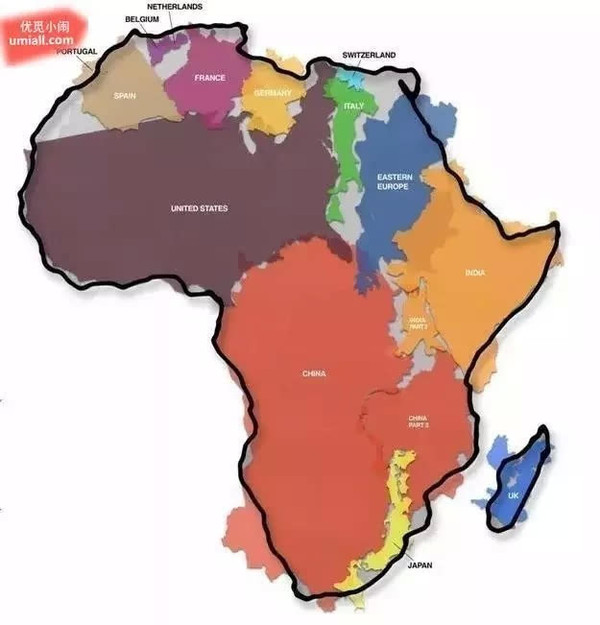
把美国、西班牙、比利时、荷兰、法国、德国、义大利、瑞士、东欧、印度、中国的一部分、英国、日本…全都放进去。
6. 如果地球没有水的话,就会变成这样…
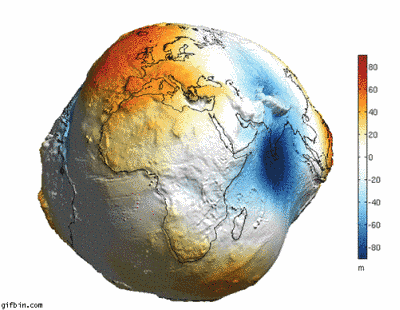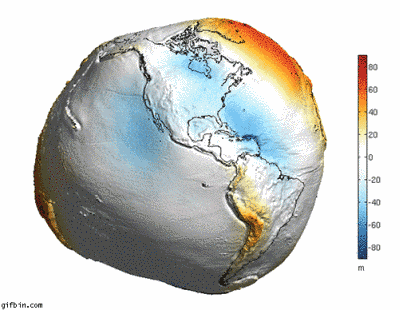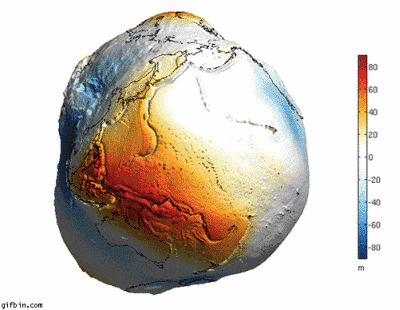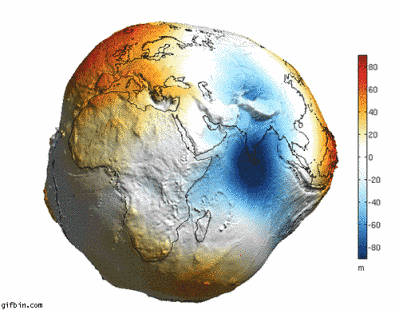
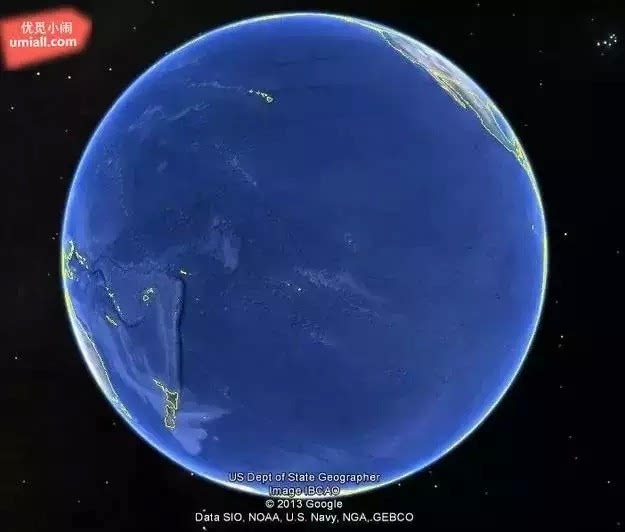
7. 你知道太平洋其实比起想像的还要大吗?
8. 这是马里亚纳海沟 (Mariana Trench) 的深度,难怪还有这么多人类尚未探索到的海底生物。

可以深到10972公尺…或更多。
9. 我们都知道有很多人造卫星,但是你知道有这么多吗?

10. 把美国放到月球的话,大小比例是这样…

11. 地球到月球的距离貌似很短,但是已经可以塞下太阳系的所有星球了。

有384,400公里那么远喔~
12. 若把火星上头的奥林帕斯山 (Olympus Mons) 拿来跟地球的高山来比较的话…地球的好像就是小儿科啊…

奥林帕斯山有27公里高,几乎是圣母峰的3倍高,也比毛纳基火山 (从水底山脚计算) 的2倍还要高。奥林帕斯山已经高耸进火星的大气层了。它的基底有550公里那么宽广,意思也就是,如果你站在破火山口来看的话,它的山脚会一路绵延超过地平线。
13. 而这座巨型火山,大概也跟一个法国差不多大。

14. 木星的体积也不小,只是距离我们太远了。但如果木星距离我们就跟月球一样近的话,我们会看到…

心脏根本就不够用啊!仰望天空时太惊悚了吧!
15. 左是木星卫星「木卫二」(Europa) 上头的水量,右则是地球上的水量。
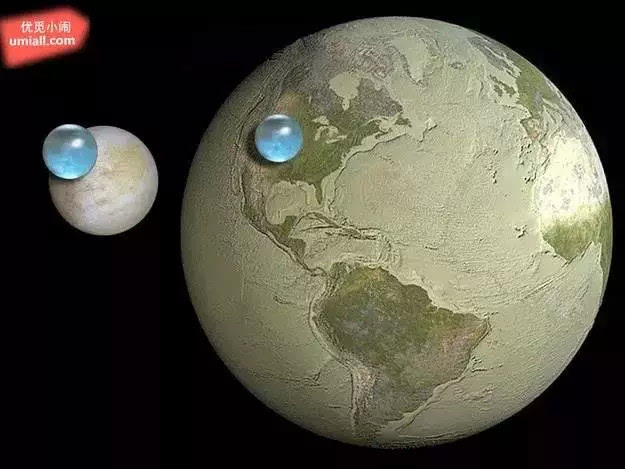
什么!地球的水比想像中的还要少这么多呀!
16. 每一天,都是木星让陨石的轨迹远离地球的。

虽然不知道你听不听得到,但谢谢你,木星。(对天呐喊~)
17. 我们都知道宇宙里头有许多彗星,但你可能对它们的大小没有什么概念。好吧,如果拿洛杉矶 (LA) 跟彗星比较的话…

18. 我们的太阳系也是不断地移动,我们现在跟2.25亿年前的地球是在同一个位置,当时恐龙都还活着。
我们的太阳系会花上2.25亿年绕行银河系,上一次地球在同一个位置的时候,恐龙都还存在着。
19. 仰望天空,我们都觉得其他的星星很小,但若从土星的环后方来看的话,地球也相当渺小。
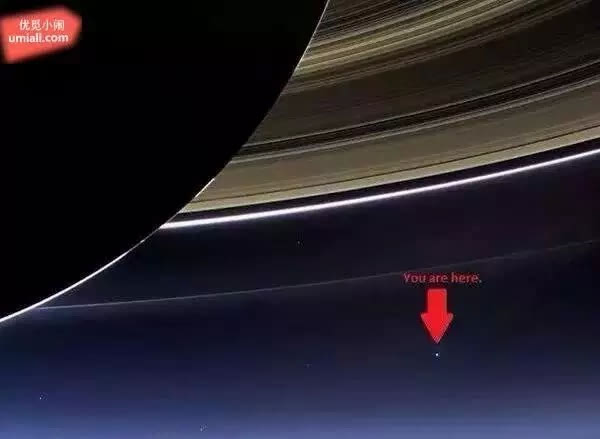
20. 事实上,你眼睛所能看见、人类所知道的,其实都只有在这小小的圈圈里头。

21. 而在银河系当中,所有人类向宇宙广播可以触及的范围,就只有那蓝色的小点点那么多。难怪我们一直都没有找到其他高智能的生命…

22. 而这是我们每年在银河系当中所发现的星球数量:
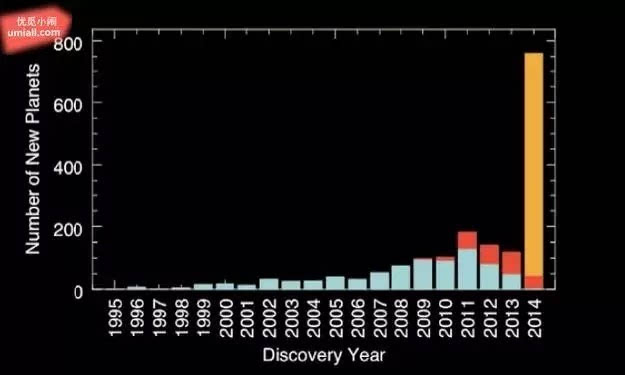
23. 银河系貌似很大,但我们再来比较一下…
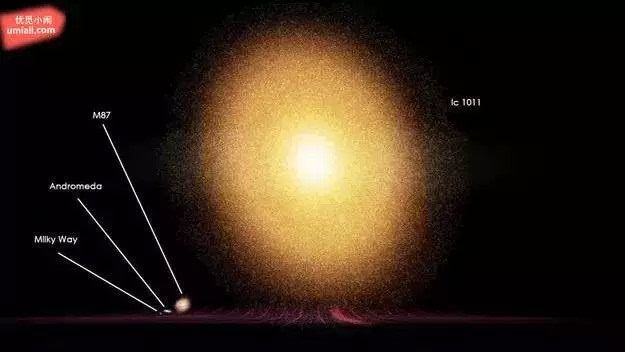
(左到右) 银河系、仙女座星系 (Andromeda)、室女A星系 (m87)、IC-1011星系。
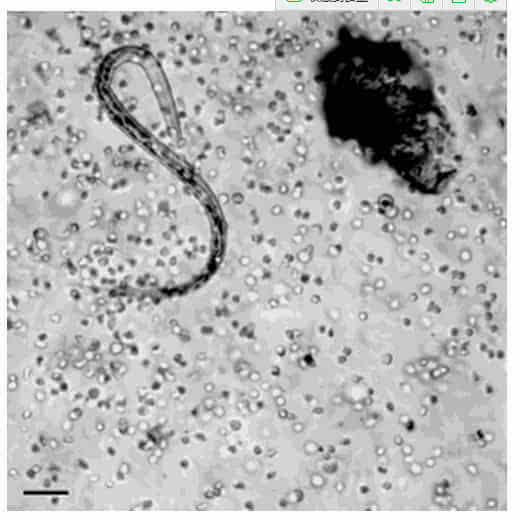
24. 看完之后,你可能跟我一样觉得自己相当渺小,但别忘了,每天有上兆的细胞在你的体内运行着。以下是白血球正在攻击寄生虫的样子:
25. 在细分一些,这些东西都是由分子组成的,而这是其中的一个:

最后也忘了,你体内是有7,000,000,000,000,000,000,000,000,000 个原子的,这就是你!
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330