文章来源: 丁点帮你
作者:丁点helper
两组独立样本的非参数检验与其t检验相对,主要是用于不满足正态分布的小样本,一般用Wilcoxon秩和检验,又称Mann-Whitney 检验。
这里我们想指出一点的是,人们往往对正态性的关注更多一些,其实样本量也很重要,这里是样本量较小的情形,如果样本量足够大(比如超过40),即使正态性不满足,也可以使用t检验,而且更推荐用t检验。
案例:在某小学随机采集12岁男童和女童各10名的头发样品,检测发样中钙(Ca)含量(μg/g),数据见下表。男童与女童头发中Ca含量有无差异?
上述数据经过正态性检验,P<0.05,此时认为数据不符合正态分布,即男童组与女童组的数据均不服从正态分布;又因为样本量合计仅有20,所以可采用非参数秩和检验。
下面,我们简单说说这其中的基本思想:
和之前讲解的单样本及配对样本秩和检验一致,这里都需要先编制求秩和,然后用秩和进行检验统计量的计算。
比如,随机抽取样本量分别为n1和n2的两个独立样本,要先将全部数据统一编秩,注意是两组混合起来统一编制。
如上表,就是将男童与女童混合在一起进行编制,然后分组计算秩和。
这里,相当于对原始数据进行了秩变换,即用秩数据代替原始数据进行分析,从而不受原始数据需满足正态分布的条件限制。
如果上述女童组的Ca含量原始数据高于男童组,则女童组Ca含量的秩和也大概率会高于男童组。
我们说过,编秩就是数数,这里一共有20个样本,总秩和加起来为210(就是从1加到20:用中学的公式,首位相加乘以项数除以2)。
如果满足假设,两组儿童Ca含量没有差异,那么两组的秩和大概率都等于105(210的一半)。
以上是基本的思路,严格来讲,检验是在计算秩和后,取任意一组样本(如男童)的秩和(R1=77)作为Wilcoxon秩和检验统计量W,在H0假设成立情况下,则W的均数和标准差分别等于:
当W远离其均数时,则有理由拒绝零假设,认为两组有差异。
比如本例W=77(男童的秩和),比 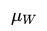 小约2倍标准差:(77-105)/13.229=-2.116,所以,粗略判断,两组数据应该是有差异的。
小约2倍标准差:(77-105)/13.229=-2.116,所以,粗略判断,两组数据应该是有差异的。
这里关于W统计量均数和标准差的计算可以不用特别关注,主要是理解整个思想过程,具体的计算都会交由软件来做。
上述案例标准的检验的步骤总结如下:
(1) 建立检验假设,确定检验水准
H0:男童与女童头发中Ca含量的总体分布相同
H1:男童与女童头发中Ca含量的总体分布不同
a=0.05
(2) 编秩、求秩和
先将男童组与女童组发样中Ca含量的数值由小到大统一编秩,将两组秩分别相加得每组秩和。
(3) 计算检验统计量
本例W=77,Z=-2.116。
(4) 确定P值,作出推断
本例P=0.034,按α=0.05 水准拒绝H0 ,接受H1 ,可以认为男童与女童的头发中Ca含量差异有统计学意义。男童组平均秩为77/10=7.7,女童组平均秩为133/10=13.3,可认为女童的头发中Ca含量高于男童。
另外,值得指出的是,在实际应用中,有一些数据是用离散尺度表达的,什么意思?
比如对于疼痛的评分,研究者会将疼痛用0至10个数据表示,0表示无痛、10表示最痛,研究对象需要根据自身的疼痛程度在这11个数字中挑选一个数字代表疼痛程度。
当用此类数据进行秩和检验,常常会出现很多相同秩,这个时候,检验统计量的计算会略有差别,这个大家稍微留意,不过一般统计软件在分析时会自动调整。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330