
CDA数据分析师 出品
作者:Mika、真达
数据:真达
后期:泽龙
【导读】今天我们用数据来聊一聊口味虾。
Show me data,用数据说话
今天我们聊一聊 口味虾
说起湖南这个地方,大家想到的肯定是各种吃的,最常听到的就是臭豆腐,外焦里嫩,闻起来臭吃起来香,一口下去让人回味无穷。

还有香甜软糯的糖油粑粑,炸至金黄的糯米,外面裹着糖浆。

还有就是口味虾了,口味虾又叫麻辣小龙虾。在夏天的时候,邀上三五好友,来上几盘口味虾,搭配上啤酒,肥宅的生活就这么快乐的开始了,味道麻辣爽口,一口下去就想吃下一口!在湖南,没有吃上口味虾的夏天都是不完整的。
那么湖南的吃货们都喜欢吃哪家的口味虾呢?今天我们就用数据来盘一盘。

我们使用Python获取了大众点评上长沙口味虾店铺的相关信息,进行了数据分析,整体流程如下:
网络数据获取
数据读入
数据探索与可视化
K-means聚类分析
01数据读入
首先导入所需包,并读入获取的数据集。
# 导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import jieba
from pyecharts.charts import Bar, Pie, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType, WarningType
WarningType.ShowWarning = False
import plotly.express as px
import plotly.graph_objects as go
此数据集包含50个搜索页面共745条数据,字段包含:餐厅名、星级、星级评分、评论数、人均消费、推荐菜、口味、环境和服务得分。
数据预览如下:
# 读入数据
df = pd.read_excel('../data/长沙小龙虾数据.xlsx')
df.drop('detail_url', axis=1. inplace=True)
df.head()

02数据预处理
此处我们对数据进行如下处理以便后的分析工作。
title: 去除前后符号
star:提取星级
score: 提取数值,转换为类别型
comment_list:提取口味、环境、服务得分
删除多余的行和列
# 星级转换
transform_star = {
20: '二星',
30: '三星',
35: '准四星',
40: '四星',
45: '准五星',
50: '五星'
}
# 处理title
df['title'] = df['title'].str.replace(r"\[\'|\'\]", "")
# star处理
df['star'] = df.star.str.extract(r'(\d+)')[0].astype('int')
df['star_label'] = df.star.map(transform_star)
# 处理score
df['score'] = df['score'].str.replace(r"\[\'|\'\]", "").replace("[]", np.nan)
df['score'] = df['score'].astype('float')
# 口味
df['taste'] = df.comment_list.str.split(',').str[0].str.extract(r'(\d+\.*\d+)').astype('float')
# 环境
df['environment'] = df.comment_list.str.split(',').str[1].str.extract(r'(\d+\.*\d+)').astype('float')
# 服务
df['service'] = df.comment_list.str.split(',').str[1].str.extract(r'(\d+\.*\d+)').astype('float')
# 删除列
df.drop('comment_list', axis=1. inplace=True)
# 删除行
df.dropna(subset=['taste'], axis=0. inplace=True)
# 删除记录少的
df = df[df.star!=20]
处理之后的数据如下,分析样本为560条。
df.head()

03数据可视化
以下展示部分可视化代码:
1不同星级店铺数量分布
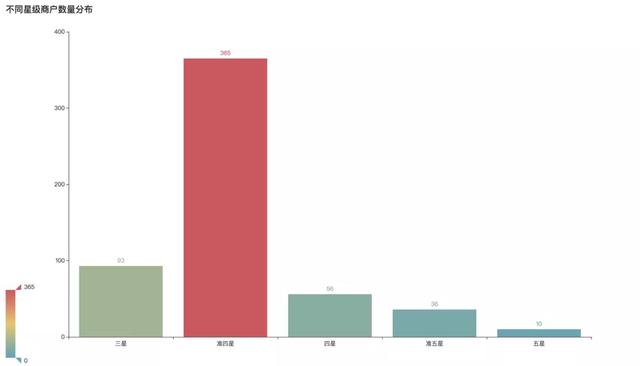
准四星商户最多,占比高达65%,超过四星以上的商户占比18%,其中五星商户数量最少,仅有10家。
# 产生数据
star_num = df.star.value_counts().sort_index(ascending=True)
x_data = star_num.index.map(transform_star).tolist()
y_data = star_num.values.tolist()
# 条形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(x_data)
bar1.add_yaxis('', y_data)
bar1.set_global_opts(title_opts=opts.TitleOpts(title='不同星级商户数量分布'),
visualmap_opts=opts.VisualMapOpts(max_=365)
)
bar1.render()
2店铺评论数分布
我们假设评论数目为店铺的热度,也就是它越火,消费人数越多,评论数目越多。
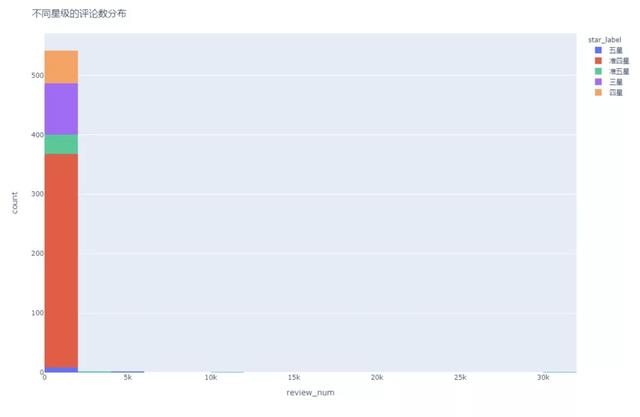
从直方图中可以看出,数据呈现比较严重的右偏分布,其中超过1万评论的仅有两家,我们挑选出来看一下,发现这两家都是超级文和友,超级文和友是长沙网红打卡地,国庆期间一天排16000+个号的超级网红龙虾馆,难怪热度会这么高。
# 直方图
px.histogram(data_frame=df , x='review_num', color='star_label', histfunc='sum',
title='不同星级的评论数分布',
nbins=20. width=1150. height=750)
3人均价格区间分布
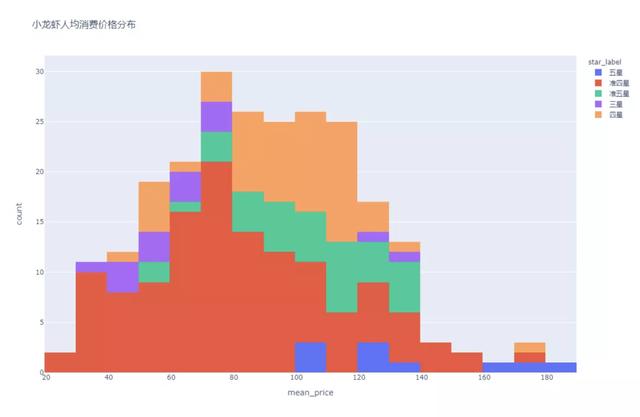
我们绘制了所有店铺口味虾人均消费价格分布的直方图,发现价格分布在20~180元之间,其中人均消费大部分都在67-111元的区间内。扩展看,人均消费和商户的星级有关系吗?
# 直方图
px.histogram(data_frame=df , x='mean_price', color='star_label', histfunc='sum',
title='小龙虾人均消费价格分布', nbins=20. width=1150. height=750)
4不同星级店铺与价格等因素的关系
不同星级与价格的关系
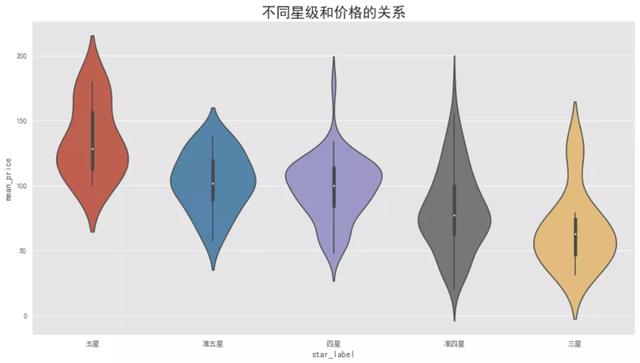
这里绘制了星级和价格分布的小提琴图,用来展示多组数据的分布状态以及概率密度。从图形可以看出,不同星级和价格之间的分布有显著差异,表现为星级越高,平均消费价格越高。
# 小提琴图
plt.figure(figsize=(15. 8))
sns.violinplot(x='star_label', y='mean_price', data=df,
order=['五星', '准五星', '四星', '准四星', '三星']
);
plt.title('不同星级和价格的关系', fontsize=20)
plt.show()
不同星级和其他得分项的关系
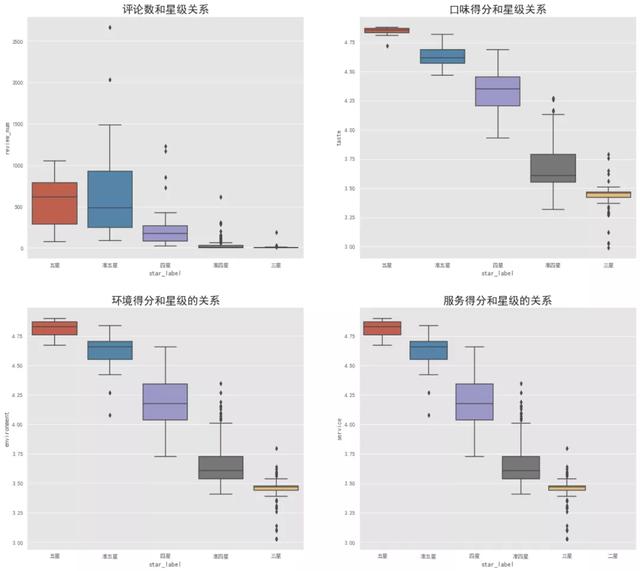
我们预想,星级评价越好,它在口味、环境和服务的得分越高,热度也就越高,从绘制出来的箱线图也可以验证我们的这一假设。
那么店铺得分与口味、环境、服务、评论数量、平均价格有关系吗?接下来我们绘制一张多变量图看一下。
4数值型变量关系
多变量图用于探索数值型变量之间的关系,从多变量图可以看出:
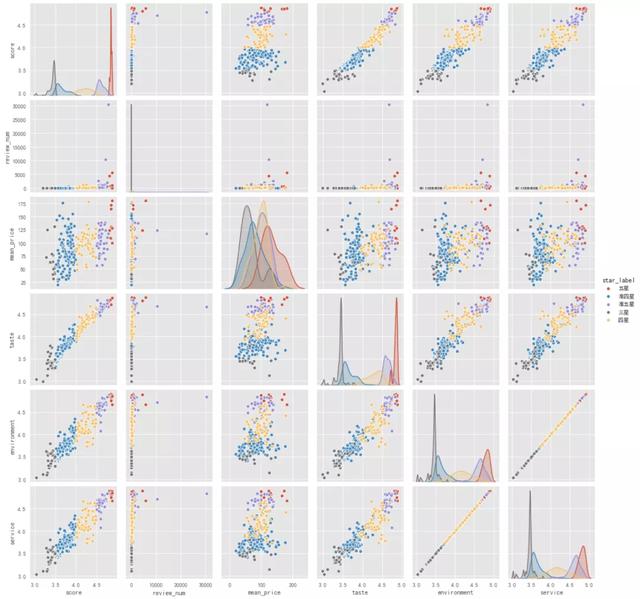
店铺得分与口味、环境、服务得分呈现较为显著的线性相关,这也和之前的验证一致;
店铺得分和人均消费价格、评论数量关系不显著;
口味、环境、服务得分之间有显著的正相关,三者存在高则同高的情况。
# 多变量图
sns.pairplot(data=df[['score', 'review_num', 'mean_price', 'taste', 'environment', 'service', 'star_label']]
, hue='star_label')
plt.show()
数值型变量之间的相关系数
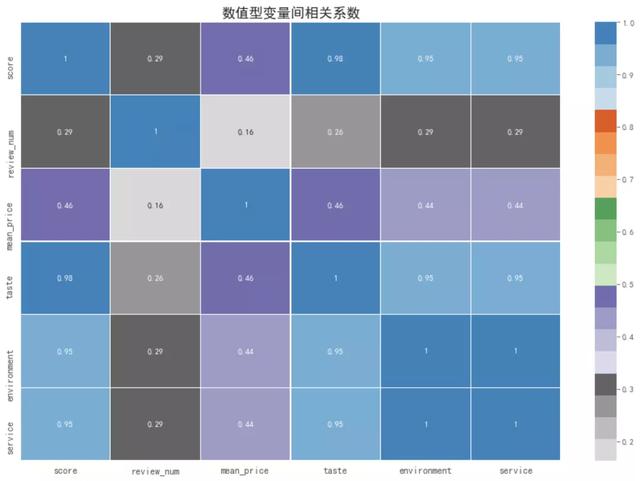
为了验证上述可视化的结果,我们通过Python计算数值型变量之间的pearson相关系数,根据经验,|r|>=0.8时,可视为高相关。从热力图中也可以得到上述结论。
# 相关系数
data_corr = df[['score', 'review_num', 'mean_price', 'taste', 'environment', 'service']].corr()
# 热力图
plt.figure(figsize=(15. 10))
sns.heatmap(data_corr, linewidths=0.1. cmap='tab20c_r', annot=True)
plt.title('数值型变量间相关系数', fontdict={'fontsize': 'xx-large', 'fontweight':'heavy'})
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.show()
5推荐菜词云图
假设店铺的推荐菜就是不同店铺的热门菜,我们使用jieba对推荐菜进行分词并绘制词云图:

发现"卤虾"、"口味虾"、"油爆虾"是大家爱点的热门菜。另外大家点口味虾的同时也爱点"口味花甲"、"凤爪"、"牛油"之类的串儿等菜。
6K-means聚类分析群集占比
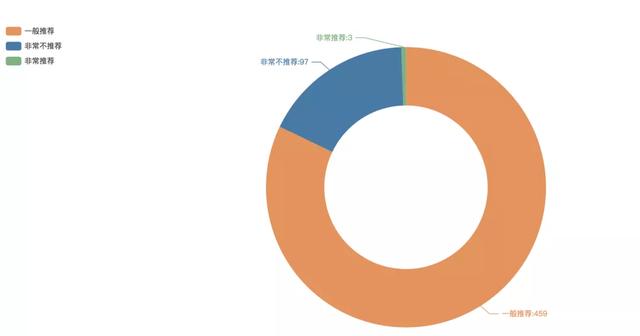
聚类分析用于将样本做群集划分,同一集群内成员的相似性要愈高愈好, 而不同集群间成员的相异性则要愈高愈好。我们使用Python进行了K-means聚类,对数值型变量:得分、评论数、平均价格、口味、环境、服务评论做群集划分,这里取K为3.得到以上三群,其中非常推荐的数量有3家,一般推荐的459家,非常不推荐的有97家。我们看一下这三群的描述性统计:
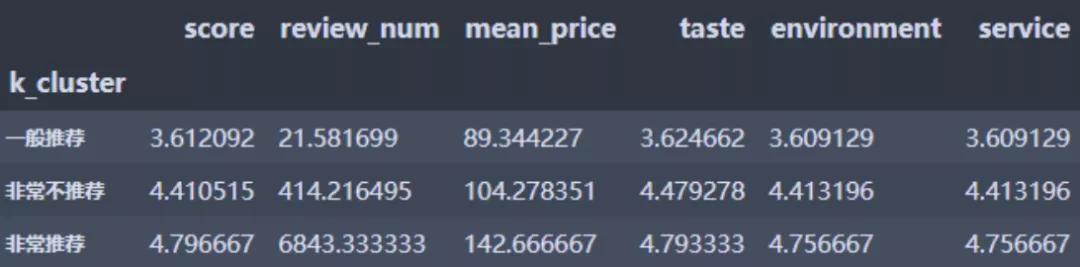
K-means聚类分析分布
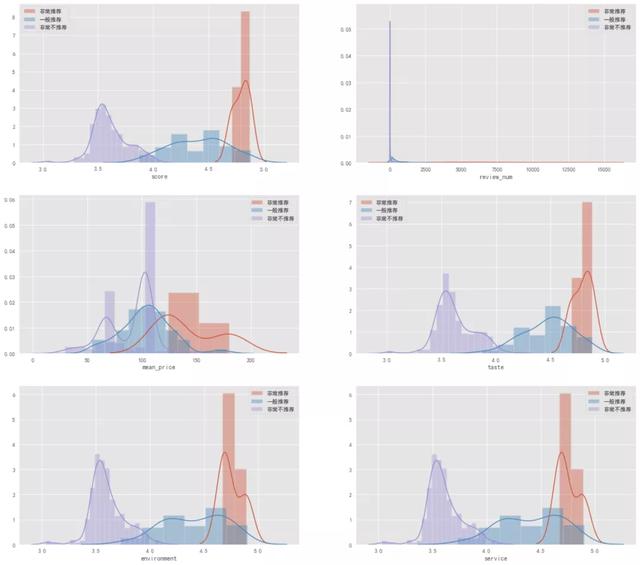
以上是不同群集的直方图分布,通过群集分布图,可以总结如下:
非常推荐:各项得分最高、评论数最多、价格最高
一般推荐:各项得分居中、评论数居中、价格居中
非常不推荐:各项得分最低、评论数最低、价格最低
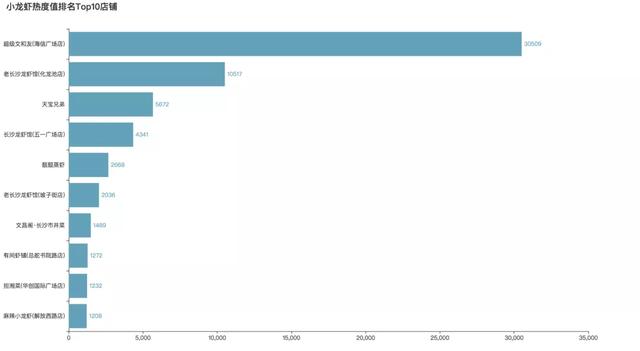
由于在做聚类分析时候去除了一个评论数为30509.0的异常样本。加上这条样本,得到最终推荐的四家店铺:

最后附上大众点评上热度值Top10的口味虾店,看看有没有你种草的店吧~
想要获取完整数据,可以私信或者留言哦。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330