
最近这部《隐秘的角落》彻底火了,目前在豆瓣高达8.9分,有45万余人进行了评论。
一时间剧中张东升那句「爬山」、「你说我还有机会吗」 承包了6月份的梗。各种表情包和段子齐飞。


作为主演秦昊当年的同学,章子怡都出来打call。

刷完剧,那首「小白船」简直成了新的恐怖童谣,让人在脑海中无限循环,太上头了。

那么这部制作精良的国产剧为何能收获到观众的一致好评?大家在看剧时都在讨论些什么?今天我们就用数据来带你看看。
01拿拍电影的态度拍网剧 ,不好看才怪
该剧改编自紫金陈推理小说《坏小孩》 ,讲述了沿海小城的三个孩子在景区游玩时无意拍摄记录了一次谋杀,他们的冒险也由此展开。扑朔迷离的案情,将几个家庭裹挟其中,带向不可预知的未来......

剧刚开始的画面就是,文质彬彬的男青年带着一对老人在山顶拍照,二老坐在石头上,背后就是万丈深渊,男青年上前亲自指导姿势,而就在一瞬间,他眼神一冷,两只手同时发力,将二老从山顶推了下去,甚至在推完还在佯作惊慌失措的样子大喊:“爸!妈!”而这一切却被三个游玩的小孩无意拍了下来。

这一开场就把观众吓了一跳,甚至都起了鸡皮疙瘩。同时也让人欲罢不能想看看接下来会发生什么故事。
剧情不拖沓,演技全员在线
不同于国产剧一般动辄四五十集的篇幅,《隐秘的角落》只有短短的12集,故事紧凑,剧情毫不拖泥带水。
而整部剧中,无论是从挑大梁的秦昊,到三位小演员,还是王景春、张颂文等一众演员都奉献出了无可挑剔的演技。
令人印象深刻的配乐
配乐也是《隐秘的角落》中的亮点之一。配合影视剧的悬疑剧情,这些配乐听起来确实分外惊悚恐怖,也给大家留下了不可磨灭的阴影,被网友调侃:“能不能整点阳间的音乐?”如果问为什么本剧配乐这么讲究,要知道《隐秘的角落》的导演辛爽可是乐队音乐人出身的。

02豆瓣8.9分 年度国剧之光!
首先,我们看到豆瓣的数据。这部剧一开播在豆瓣评分就冲上9.0分,一度冲到9.2分,随着剧集完结,目前稳定在8.9分,已经有45万余人进行了评分。

总体评分
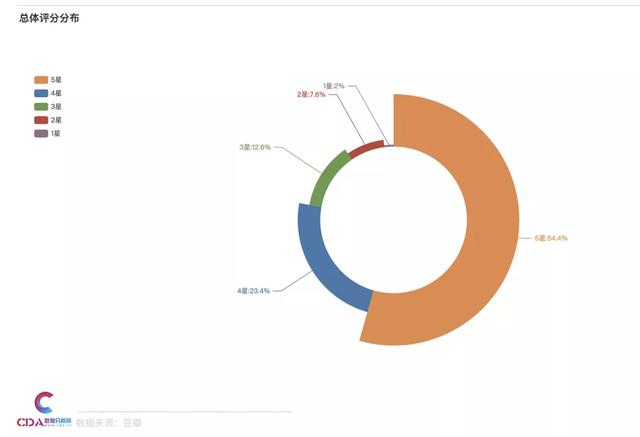
细看评分的分布可以发现,有54.4%的人都给出了五星好评,其次23.4%的人给出四星。这个成绩还是很不错的。
评论热度走势图
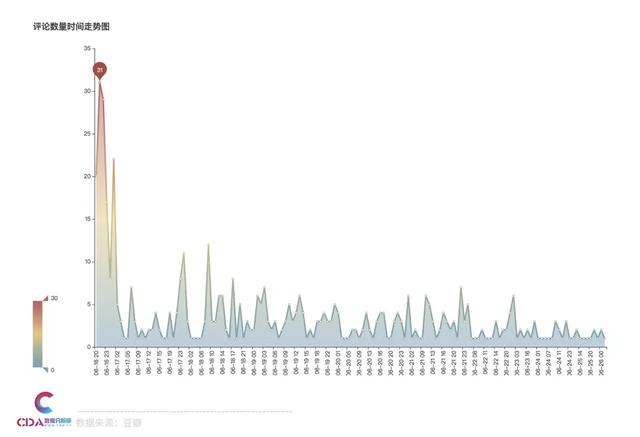
从评论走势图可以看到,《隐秘的角落》在6月16日首播,评论热度最高。之后不同于其他剧,随着播出时间评论数量趋于平缓,这部剧再播出后也不时带来热度,引发观众的评论潮。
评论中提及主演
大家在评论时都提到哪些角色了呢?
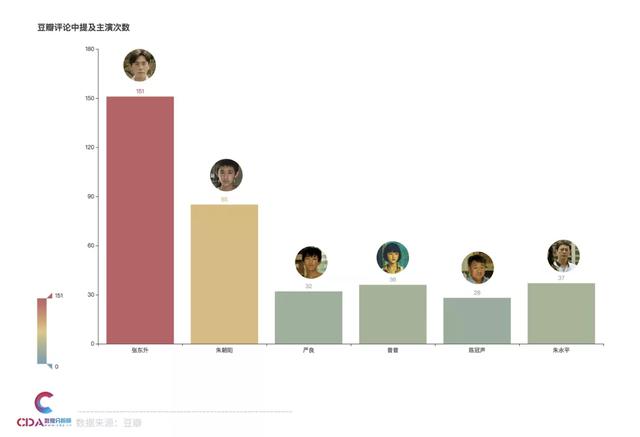
分析发现,主演张东升的讨论度果然是最高的,其次是三个小演员之一的朱朝阳。演技派演员王景春和张颂文饰演的陈警官和朝阳爸爸讨论度也很高。
主演评价分布
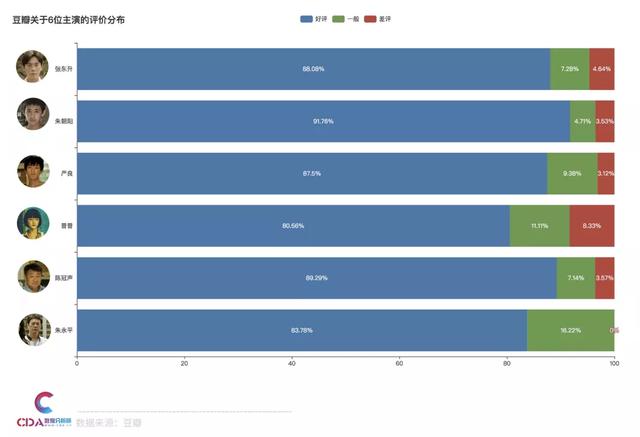
我们分析了豆瓣短评中用户关于主演的好评/一般/差评分布占比。
细致到个人表演来看,小演员们的表现相当突出,比如朱朝阳的扮演者荣梓杉,有超过9成的观众肯定了他的表现。秦昊、王景春两位的表现自然也是很厉害的。他们在剧中的表现,分别获得了88.08%和89.29%的好评率。
0320万条弹幕告诉你
追剧时大家都在说些什么?
接下来我们分析一下《隐秘的角落》在爱奇艺的弹幕数据,我们分析整理了全部12集的弹幕,共200672条。下面看到分析结论:
用户使用的弹幕角色
观众在爱奇艺追剧发弹幕时,可以选择自己喜欢的角色头像。那么观众都最喜欢用哪些用人物角色发弹幕呢?
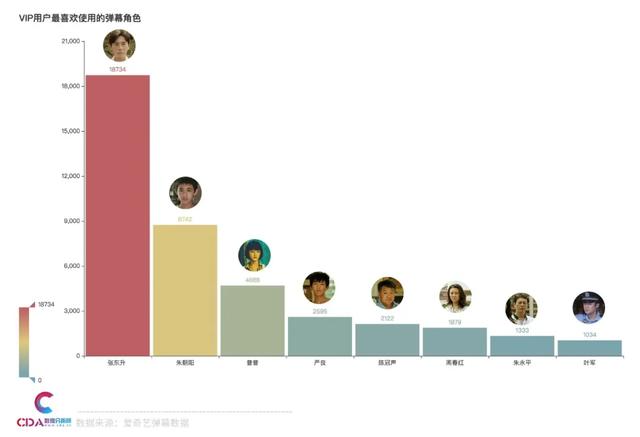
可以看到,这方面张东升在这方面是榜首。其次是朱朝阳,然后可爱的小妹妹普普位居第三。
弹幕字数分布
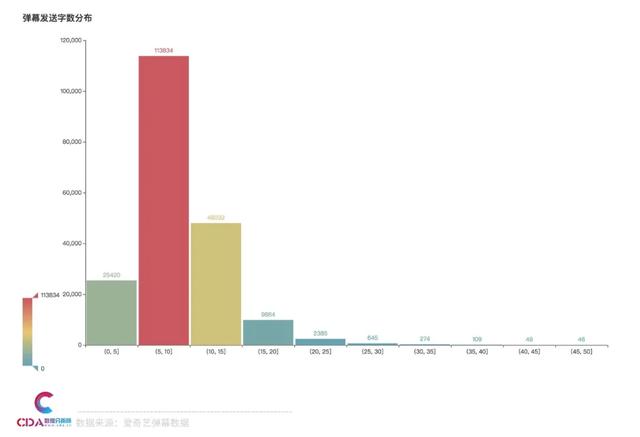
在弹幕的字数上我们可以看到,5-10个字的是最多的,共有11万余条弹幕。其次是10-15个字,48032条弹幕。0-5个字的弹幕也有不少,共25420条。可见在追剧发弹幕时,大家还是倾向多说点,表达自己的想法。
整体弹幕词云

在整体弹幕词云中,「孩子」、「严良」、「普普」被提到的频率很高。看到三位小主演的一举一动还是牵动着观众的心的。
接下来,我们分别看到几位主演的人物弹幕词云吧。
张东升

首先就是张东升了,不同于一般脸谱化的反派角色。在张东升的身上,大家既看到他的冷酷,凶残,也看到他的无奈和隐忍。在弹幕中,关于他,提到「爬山」、「机会」的特别多,这几句张东升的话实在太出圈了。
有意思的是,张东升的「头发」也被频频提及,毕竟这个秃头造型实在是太令人印象深刻了。

朱朝阳

下面再看到三位小主演中最受关注的朱朝阳。品学兼优的他,因为父母离异性格有些内向和孤僻。在词云中,他与「爸爸」、「妈妈」的感情也是大家讨论最多的。其次他与「张东升」间的对手戏,以及后面他角色的「黑化」也是讨论焦点。
普普

剧中的小妹妹普普也是很多人喜欢的角色了,在词云中可以看到观众对她的「喜欢」,以及对她「演技」的肯定。此外,「善良」等词也常被提到。
严良

剧中的另一位小演员角色——严良也是弹幕中关注度很高的。关于他,大家经常会提到跟他形影不离的「普普」,此外「演技不错」「厉害」等词也频出。
04教你用Python分析爱奇艺弹幕数据
我们使用Python获取并分析爱奇艺的弹幕数据,整个数据分析的流程分为以下三个部分:
下面看到具体步骤:
首先导入所需包,其中pandas用于数据读入和数据处理,os用于文件操作,jieba用于中文分词,pyecharts和stylecolud用于数据可视化。
# 导入库
import pandas as pd
import os
import jieba
from pyecharts.charts import Bar, Pie, Line, WordCloud, Page
from pyecharts import options as opts
from pyecharts.globals import SymbolType, WarningType
WarningType.ShowWarning = False
import stylecloud
from IPython.display import Image
我们将爬取的数据存放在data文件夹下,使用os操作获取需要读取的csv文件列表。
# 文件列表
data_list = os.listdir('../data/')
data_list
['df_第一集.csv',
'df_第七集.csv',
'df_第三集.csv',
'df_第九集.csv',
'df_第二集.csv',
'df_第五集.csv',
'df_第八集.csv',
'df_第六集.csv',
'df_第十一集.csv',
'df_第十二集.csv',
'df_第十集.csv',
'df_第四集.csv']
然后使用pandas将csv文件读入并循环追加到总表df_all中,打印以下数据集大小看一下,一共有200672条。
# 存储数据
df_all = pd.DataFrame()
# 循环写入
for i in data_list:
df_one = pd.read_csv(f'../data/{i}', engine='python', encoding='utf-8', index_col=0)
df_all = df_all.append(df_one, ignore_index=False)
# 打印数据集大小
print(df_all.shape)
(200672, 6)
再预览一下前五行数据。
# 预览数据
df_all.head()
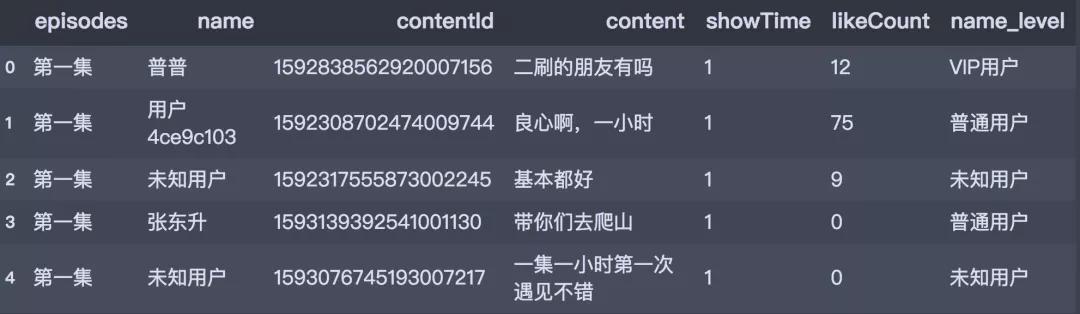
数据读入之后,接下来简单对数据集进行预处理的工作,我们针对name字段进行以下处理:使用strip操作去除字符串前后的空格;定义一个转换函数,根据name字段新增name_level字段,标注用户等级,效果如下:
# 字符串处理
df_all['name'] = df_all.name.str.strip()
def transform_name(x):
if x=='张东升' or x=='朱朝阳' or x=='普普' or x=='严良' or x=='陈冠声' or x=='周春红' or x=='朱永平' or x=='叶军':
return 'VIP用户'
elif x=='未知用户':
return '未知用户'
else:
return '普通用户'
# 新增列
df_all['name_level'] = df_all.name.apply(transform_name)
df_all.head()
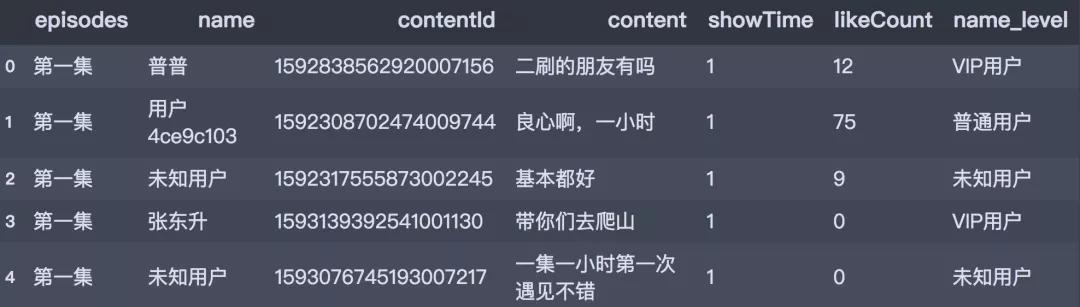
接下来使用pyecharts进行数据可视化。主要分析内容包含:
-
用户最喜欢使用的弹幕角色-条形图
-
弹幕发送字数分布-条形图
-
弹幕角色-词云图
首先统计不同等级用户的数量。
level_num = df_all.name_level.value_counts()
level_num
未知用户 157722
VIP用户 41127
普通用户 1823
Name: name_level, dtype: int64
使用pyecharts中的Pie类绘制饼图,效果如下:
data_pair = [list(z) for z in zip(level_num.index.tolist(), level_num.values.tolist())]
# 绘制饼图
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add('', data_pair, radius=['35%', '60%'])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='弹幕发送人群等级分布'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
pie1.set_colors(['#3B7BA9', '#6FB27C', '#FFAF34'])
pie1.render()
name字段中标注了用户发送弹幕时候使用的弹幕角色,统计并筛选不同弹幕角色的使用频次。
role_num = df_all.name.value_counts()[1:9]
role_num
张东升 18734
朱朝阳 8742
普普 4688
严良 2595
陈冠声 2122
周春红 1879
朱永平 1333
叶军 1034
Name: name, dtype: int64
然后使用pyecharts中的Bar类绘制一张饼图。
# 柱形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(role_num.index.tolist())
bar1.add_yaxis("", role_num.values.tolist(), category_gap='5%')
bar1.set_global_opts(title_opts=opts.TitleOpts(title="VIP用户最喜欢使用的弹幕角色"),
visualmap_opts=opts.VisualMapOpts(max_=18734),
)
bar1.render()
content字段记录了用户评论的弹幕信息,此处根据这个字段计算字数并按照步长5进行分箱处理,得到不同字数段下的频次分布。
word_num = df_all.content.apply(lambda x:len(x))
# 分箱
bins = [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50]
word_num_cut = pd.cut(word_num, bins, include_lowest=False).value_counts()
word_num_cut = word_num_cut.sort_index()
word_num_cut
(0, 5] 25420
(5, 10] 113834
(10, 15] 48032
(15, 20] 9864
(20, 25] 2385
(25, 30] 645
(30, 35] 274
(35, 40] 109
(40, 45] 49
(45, 50] 46
Name: content, dtype: int64
同样使用Bar类绘制一张条形图。
# 柱形图
bar2 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar2.add_xaxis(word_num_cut.index.astype('str').tolist())
bar2.add_yaxis("", word_num_cut.values.tolist(), category_gap='4%')
bar2.set_global_opts(title_opts=opts.TitleOpts(title="弹幕发送字数分布"),
visualmap_opts=opts.VisualMapOpts(max_=113834),
)
bar2.render()
接下来我们定义一个分词函数get_cut_words,这个函数的功能是传入一列数据,得到使用jieba分词之后的列表。
# 定义分词函数
def get_cut_words(content_series):
# 读入停用词表
stop_words = []
with open(r"C:\Users\wzd\Desktop\CDA\CDA_Python\Python文本分析\10.文本摘要\stop_words.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加关键词
my_words = ['秦昊', '张东升', '王景春', '陈冠声', '荣梓杉',
'朱朝阳', '史彭元', '严良', '王圣迪', '普普',
'岳普', '张颂文', '朱永平', '十二集', '十二万',
'十二时辰']
for i in my_words:
jieba.add_word(i)
# 自定义停用词
my_stop_words = ['真的', '这部', '这是', '一种', '那种',
'哈哈哈']
stop_words.extend(my_stop_words)
# 分词
word_num = jieba.lcut(content_series.str.cat(sep='。'), cut_all=False)
# 条件筛选
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return word_num_selected
将角色张东升的弹幕数据传入函数,得到分词之后的列表。
text1 = get_cut_words(content_series=df_all[df_all.name=='张东升']['content'])
text1[:5]
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\wzd\AppData\Local\Temp\jieba.cache
Loading model cost 1.280 seconds.
Prefix dict has been built successfully.
['爬山', '老弟', '十二集', '知足', '伊能静']
然后使用stylecloud工具包绘制一张心形的词云图,效果如下:

# 绘制词云图
stylecloud.gen_stylecloud(text=' '.join(text1), max_words=1000,
collocations=False,
font_path=r'C:\Windows\Fonts\msyh.ttc',
icon_name='fas fa-heart',
size=653,
output_name='./词云图/弹幕角色-张东升词云图.png')
Image(filename='./词云图/弹幕角色-张东升词云图.png')
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330