作者 | 俊欣
来源 | AI篮球与生活
年末尾上映的古装剧《庆余年》可谓是赚足了眼球,号称投资了7个亿,集齐陈道明吴刚袁泉等一票老戏骨,实力演员张若昀李沁主演,又有新顶流肖战做配,在播出后没多久便圈粉无数
在微博上对该话题的讨论和阅读数量已经达到了几十亿(当然会存在水军的成分),播一集就能上微博热搜。在打分苛刻的豆瓣上面,截至目前为止,共有15万人参与了打分,评分也维持在了7.9分左右摇摆,各大视频网站也想趁这波热潮想要从观众手中赚上一笔,特地推出了一个“超前点播“,惹得网友和众多媒体吐槽声不断,
而前几天的整部剧全集被泄露又是掀起了一波高潮,一些主流的视频网站和版权方也因此损失惨重。当然我们整个社会需要加强打击盗版这种违法行为,不过“超前点播”这种吃相并不好看的行为倒并不值得提倡!!
Anyway,今天小编呢从豆瓣上面爬取了关于庆余年的相关信息,通过“大数据”(其实并不大,或者还有点小)来帮大家分析一下,为什么观众喜欢看这部剧,喜欢看这部剧的观众又是谁以及看了之后又是怎么评价的。
01
数据的获取
首先是关于数据的获取,要想获取豆瓣上面的数据,首先需要登录自己的豆瓣账户和密码,并且获取cookie,然后跳转到《庆余年》相关的页面,就是这个样子,

然后我们利用request库发送请求,便能够获得我们想要的数据,相当简单。小编此次爬取了观看过、正在观看的观众的相关信息以及评论的具体内容。

登录豆瓣页面并获取cookie
爬取评论内容
02
数据的分析和挖掘
爬完数据之后,接下来便是简单的数据清理和分析,以及数据可视化。用Python做数据可视化的工具有很多,目前比较轻量级好用的库是pyecharts,在这里,小编就不做赘述。我们看一下pyecharts来对已经获取的数据做的可视化结果。
1、总体评分
《庆余年》在豆瓣当中的总体评分维持在7.9分左后,并不算低,并且有15万人参与了评分。从评分的分布来看,大多数评分给了4星,占总数的48.7%,其次是5星,占总数的36.5%,剩下便是3星及以下的评分,一共占到了总数的14.8%,已经是一个相当低的比例了。
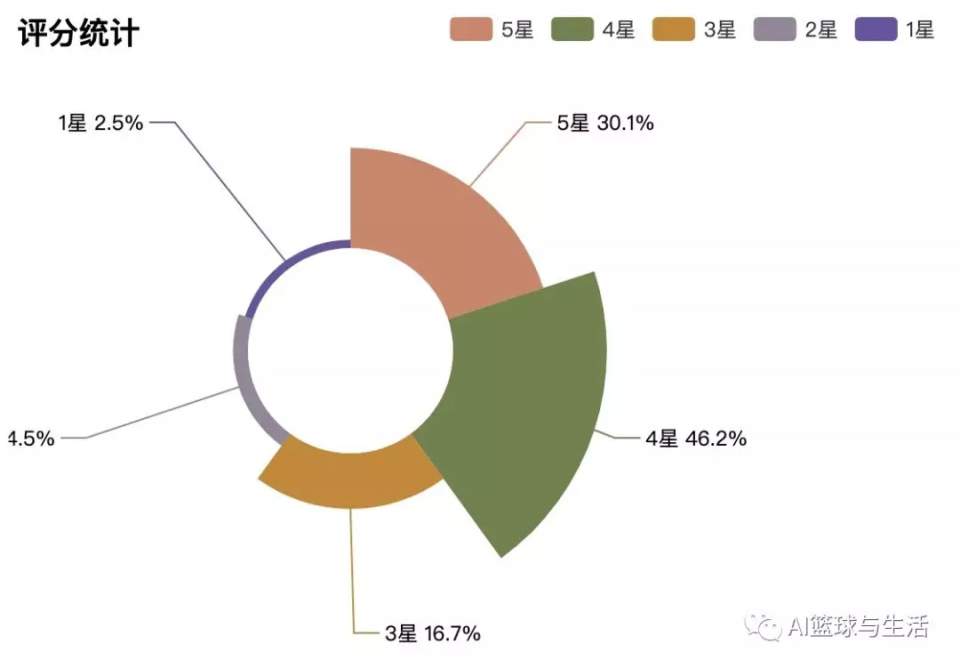
2、城市以及省份的差异
首先是直方图来粗略的展示前十大追剧热度最高的城市,如下图所示
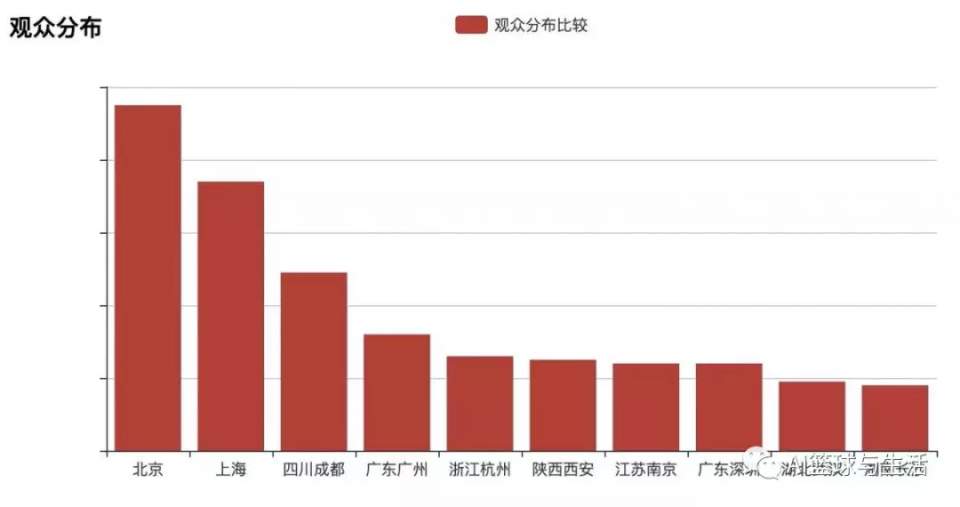
但是直方图的呈现并不总是那么的直观和易于理解,所以小编也采用地图的形式向大家展示主要看剧的观众分布在哪几个区域,
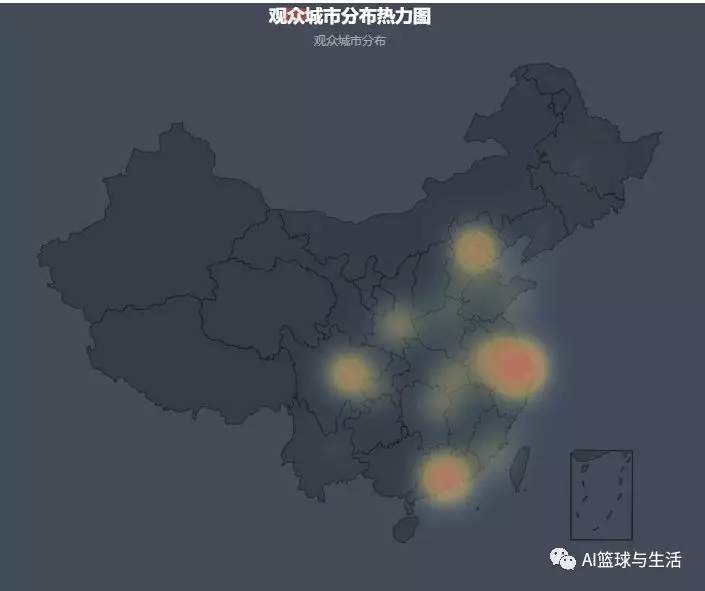
可以看得出来,在长三角和珠三角这两片区域聚集了大量热爱该部剧的粉丝。
3、评论分析
在整理和分析了评论内容之后,小编首先是对包含剧中人物的评论做了归类,并通过直方图来呈现,
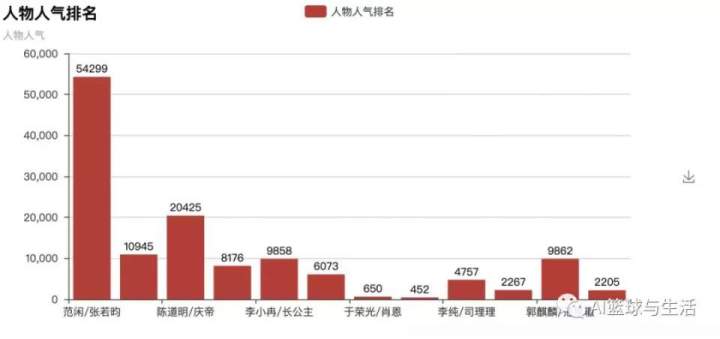
从直方图中我们可以看到,范闲和庆帝是被提到的次数最多的两位人物,接下去便是林婉儿和长公主(毕竟人家皮肤这么好,看着一点都像40多岁的女性?)。既然张若昀在剧中的人气这么高,小编便对针对范闲的评论做了进一步的探索,并用wordcloud库绘制词云图。从词云的分析情况来看,“剧情”,“搞笑”,“演技”,“原著”等字眼格外的醒目。

的确,这部剧不仅仅是剧情有趣,每一个演员演技还相当在线,该部剧不仅有张若昀、李沁、肖战等青年演员,还有一大批演技精湛的老戏骨参演,其中7名是国家一级演员,(“一级演员”是文艺界设立的专业技术职称,是国家对演员的最高职称享受国务院特殊津贴。能获得国家一级演员的称号是莫大的荣誉)。
剧情精彩不拖沓,主演专业不尴尬,人物设定完美,剧中台词又不时会诞生各种金句和表情包,于情于理《庆余年》确实很难不火。

而《庆余年》的第二季也很快会开始拍摄,这下喜欢该剧的观众和粉丝可以期待一下了!
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;












 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330