CDA数据分析师 出品
【导语】:今天我们就来聊聊另类春节档的唯一一部电影《囧妈》,Python技术部分可以直接看第三部分。
2020年的春节档之前被誉为神仙打架,各显神通,可以说是史上最强的春节档,不料一场疫情,就换了另一个局面。为配合疫情的防控,春节档电影全部撤档。
本以为就这样没下文了,结果徐峥打出一张牌:线上免费看《囧妈》,作为发行方的欢喜传媒股票当天也应声上涨42%。今天我们就来聊聊另类春节档的唯一一部电影《囧妈》。
1
另类春节档
《囧妈》绕过院线 全网免费看
在《姜子牙》《唐人街探案3》等片纷纷撤出春节档之时,《囧妈》突然宣布将于大年初一零点起,在抖音、西瓜视频、今日头条、欢喜首映等App上免费上映,成为史上首部绕过院线直接网播的春节档电影。
《囧妈》主要讲的是小老板伊万缠身于商业纠纷,却意外同母亲坐上了开往俄罗斯的火车。在旅途中,他和母亲发生激烈冲突,同时还要和竞争对手斗智斗勇。为了最终抵达莫斯科,他不得不和母亲共同克服难关,并面对家庭生活中一直所逃避的问题。
徐峥这次把《囧妈》免费让观众看的举措,让《囧妈》在惨淡的春节档赚足了足够的热度,字节跳动也收获了大量的流量。该片三天总播出量超过6亿人次,观众总数为1.8亿人次。
2
敢做第一个吃螃蟹的人
回望中国电影「大票房」时代,国内首部票房破10亿的国产电影就是徐峥在2012年的作品《人再囧途之泰囧》,达到12.67亿,之后国产电影就像打了鸡血一样,一个又一个破新高。
当然这里面C君觉得有50%的功劳要算在2010年前作《人在囧途》的精彩上,让影迷们觉得囧系列和徐峥是品质保证。C君记得当时看完《人在囧途》,就说下次徐峥再拍囧系列一定要去电影院支持,这种口碑效应在电影里面特别明显。可能正是这样的艺高,所以才胆大。
这次《囧妈》直接选择线上首映,同时还把钱给挣了,弄的电影院联名声讨,了解一下过程,你就懂了。
原来的形式是发行方欢喜传媒拍好了电影,卖给横店影视,保底24亿票房。然后横店影视去找全国的电影院,你们帮我放这部电影,最后我们肯定至少能收入24亿票房,咱们一起分。给发行方欢喜传媒6个多亿,然后我们再分剩下的18亿,是个不错的生意。
而现在,是今日头条直接取代了横店影视的位置,我给你6个多亿,我不用电影院放,我自己上亿装机量的APP上就可以看,大家拿手机免费看,我的APP打开率高了,钱就挣回来了,说不定还能培养出大家用APP看电影首映的习惯。
发行方欢喜传媒,徐峥没啥损失。电影院被今日头条系给取代了,你说能不声讨吗?
3
但观众看完之后
又是什么反应呢?
虽然《囧妈》赚足了流量,但口碑究竟如何呢?
目前《囧妈》在豆瓣上的评分仅为5.9分,负面的评论居多。我们搜集整理了豆瓣上的评论数据,用Python进行分析。整个数据分析的过程分为三步:
· 获取数据
· 数据预处理
· 数据可视化
以下是具体的步骤和代码实现:
01 获取数据
豆瓣从2017.10月开始全面限制爬取数据,非登录状态下最多获取200条,登录状态下最多为500条,本次我们共获取数据698条。
为了解决登录的问题,本次使用Selenium+BeautifulSoup获取数据。
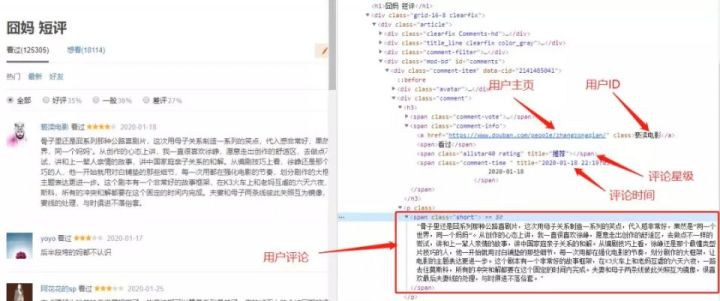
如下图所示,本此数据爬取主要获取的内容有:
· 评论用户ID
· 评论用户主页
· 评论内容
· 评分星级
· 评论日期
· 用户所在城市
代码实现:
# 导入所需包
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
# 定义登录函数
def login_douban:
'''功能:自动登录豆瓣网站'''
global browser # 设置为全局变量
browser = webdriver.Chrome
# 进入登录页面
login_url = 'https://accounts.douban.com/passport/login?source=movie'
browser.get(login_url)
# 点击密码登录
browser.find_element_by_class_name('account-tab-account').click
# 输入账号和密码
username = browser.find_element_by_id('username')
username.send_keys('18511302788')
password = browser.find_element_by_id('password')
password.send_keys('12349148feng')
# 点击登录
browser.find_element_by_class_name('btn-account').click
# 定义函数获取单页数据
def get_one_page(url):
'''功能:传入url,豆瓣电影一页的短评信息'''
# 进入短评页
browser.get(url)
# 使用bs解析网页数据
bs = BeautifulSoup(browser.page_source, 'lxml')
# 获取用户名
username = [i.find('a').text for i in bs.findAll('span', class_='comment-info')]
# 获取用户url
user_url = [i.find('a')['href'] for i in bs.findAll('span', class_='comment-info')]
# 获取推荐星级
rating =
for i in bs.findAll('span', class_='comment-info'):
try:
one_rating = i.find('span', class_='rating')['title']
rating.append(one_rating)
except:
rating.append('力荐')
# 评论时间
time = [i.find('span', class_='comment-time')['title'] for i in bs.findAll('span', class_='comment-info')]
# 短评信息
short = [i.text for i in bs.findAll('span', class_='short')]
# 投票次数
votes = [i.text for i in bs.findAll('span', class_='votes')]
# 创建一个空的DataFrame
df_one = pd.DataFrame
# 存储信息
df_one['用户名'] = username
df_one['用户主页'] = user_url
df_one['推荐星级'] = rating
df_one['评论时间'] = time
df_one['短评信息'] = short
df_one['投票次数'] = votes
return df_one
# 定义函数获取25页数据(目前所能获取的最大页数)
def get_25_page(movie_id):
'''功能:传入电影ID,获取豆瓣电影25页的短评信息'''
# 创建空的DataFrame
df_all = pd.DataFrame
# 循环追加
for i in range(25):
url = "https://movie.douban.com/subject/{}/comments?start={}&limit=20&sort=new_score&status=P".format(movie_id,i*20)
print('我正在抓取第{}页'.format(i+1), end='\r')
# 调用函数
df_one = get_one_page(url)
df_all = df_all.append(df_one, ignore_index=True)
# 程序休眠一秒
time.sleep(1.5)
return df_all
if __name__ == '__main__':
# 先运行登录函数
login_douban
# 程序休眠两秒
time.sleep(2)
# 再运行循环翻页函数
movie_id = 30306570 # 囧妈
df_all = get_25_page(movie_id)
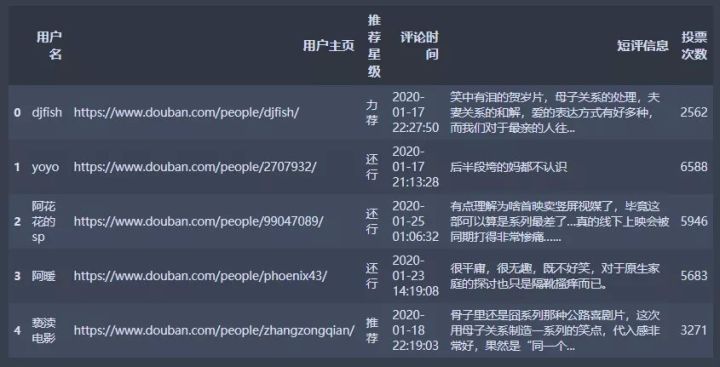
爬取出来的数据以数据框的形式存储,结果如下所示:
从用户主页的地址可以获取到用户的城市信息,这一步比较简单,此处的代码省略。
02 数据预处理
对于获取到的数据,我们需要进行以下的处理以方便后续分析:
· 推荐星级:转换为1-5分。
· 评论时间:转换为时间类型,提取出日期信息
· 城市:有城市空缺、海外城市、乱写和pyecharts尚4. 不支持的城市,需要进行处理
· 短评信息:需要进行分词和提取关键词
代码实现:
# 定义函数转换推荐星级字段
def transform_star(x):
if x == '力荐':
return 5
elif x == '推荐':
return 4
elif x == '还行':
return 3
elif x == '较差':
return 2
else:
return 1
# 星级转换
df_all['星级'] = df_all.推荐星级.map(lambda x:transform_star(x))
# 转换日期类型
df_all['评论时间'] = pd.to_datetime(df_all.评论时间)
# 提取日期
df_all['日期'] = df_all.评论时间.dt.date
# 定义函数-获取短评信息关键词
def get_comment_word(df):
'''功能:传入df,提取短评信息关键词'''
# 导入库
import jieba.analyse
import os
# 去停用词
stop_words = set
# 加载停用词
cwd = os.getcwd
stop_words_path = cwd + '\\stop_words.txt'
with open(stop_words_path, 'r', encoding='utf-8') as sw:
for line in sw.readlines:
stop_words.add(line.strip)
# 添加停用词
stop_words.add('6.3')
stop_words.add('一张')
stop_words.add('一部')
stop_words.add('徐峥')
stop_words.add('徐导')
stop_words.add('电影')
stop_words.add('电影票')
# 合并评论信息
df_comment_all = df['短评信息'].str.cat
# 使用TF-IDF算法提取关键词
word_num = jieba.analyse.extract_tags(df_comment_all, topK=100, withWeight=True, allowPOS=)
# 做一步筛选
word_num_selected =
# 筛选掉停用词
for i in word_num:
if i[0] not in stop_words:
word_num_selected.append(i)
else:
pass
return word_num_selected
key_words = get_comment_word(df_all)
key_words = pd.DataFrame(key_words, columns=['words','num'])
03 数据可视化
用Python做可视化分析的工具很多,目前比较好用可以实现动态可视化的是pyecharts。我们主要对以下几个方面信息进行可视化分析:
· 评论总体评分分布
· 评分时间走势
· 城市分布
· 评论内容
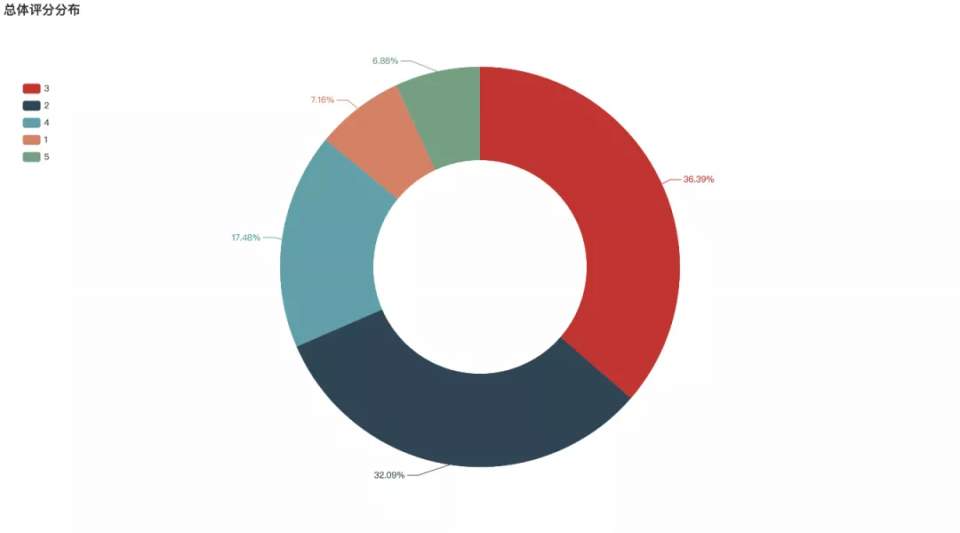
总体评分分布
《囧妈》截止到目前在豆瓣中的总体评分为5.9分,仅好于19%的喜剧片。从评分分布来看,3分的占比最高,有36.39%,其次为2分,有32.09%,5分的比例最低,仅有6.88%。
代码实现:
# 总体评分百分比
score_perc = df_all.星级.value_counts / df_all.星级.value_counts.sum
score_perc = np.round(score_perc*100,2)
# 导入所需包
from pyecharts import options as opts
from pyecharts.charts import Pie, Page
# 绘制柱形图
pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))
pie1.add("",
[*zip(score_perc.index, score_perc.values)],
radius=["40%","75%"])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='总体评分分布'),
legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),
toolbox_opts=opts.ToolboxOpts)
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{c}%"))
pie1.render('总体评分分布.html')
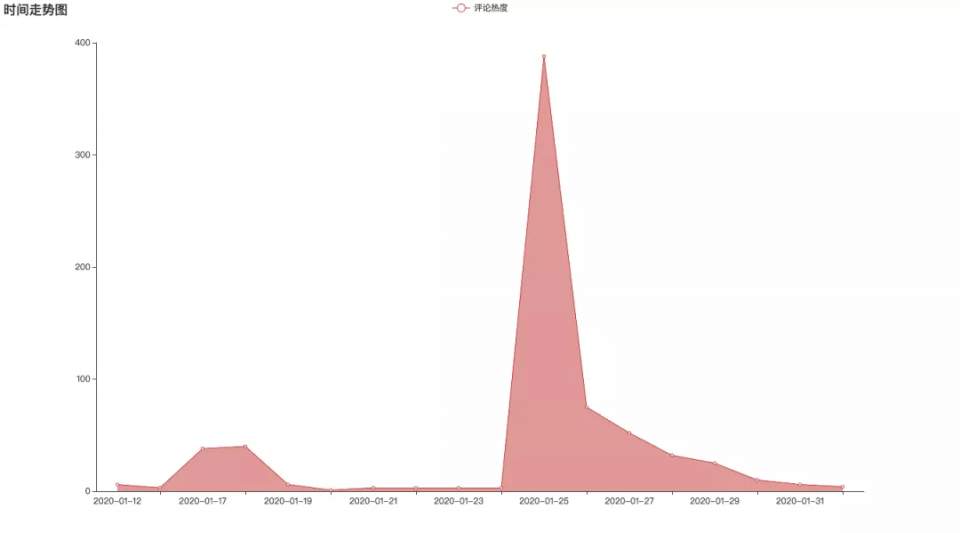
评分时间走势图
评论的时间走势图和电影热度一致,在大年初一免费上映时候达到最高值。
代码实现:
# 时间排序
time = df_all.日期.value_counts
time.sort_index(inplace=True)
from pyecharts.charts import Line
# 绘制时间走势图
line1 = Line(init_opts=opts.InitOpts(width='1350px', height='750px'))
line1.add_xaxis(time.index.tolist)
line1.add_yaxis('评论热度', time.values.tolist, areastyle_opts=opts.AreaStyleOpts(opacity=0.5), label_opts=opts.LabelOpts(is_show=False))
line1.set_global_opts(title_opts=opts.TitleOpts(title="时间走势图"), toolbox_opts=opts.ToolboxOpts)
line1.render('评论时间走势图.html')
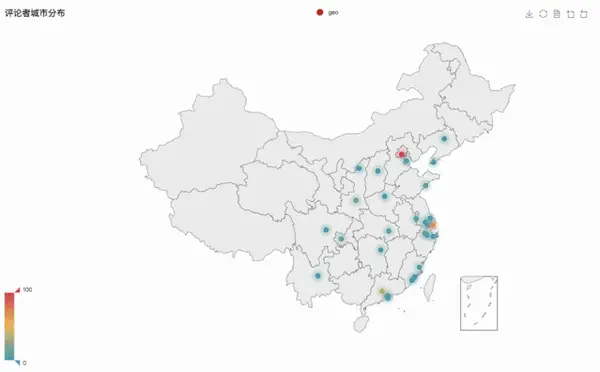
评论用户城市分布
接下来分析了评论者所在的城市分布。
首先是用条形图,来粗略的展示前十大热门的影迷城市。
代码实现:
# 国内城市top10
city_top10 = df_all.城市处理.value_counts[:12]
city_top10.drop('国外', inplace=True)
city_top10.drop('未知', inplace=True)
from pyecharts.charts import Bar
# 条形图
bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1.add_xaxis(city_top10.index.tolist)
bar1.add_yaxis("城市", city_top10.values.tolist)
bar1.set_global_opts(title_opts=opts.TitleOpts(title="评论者Top10城市分布"),toolbox_opts=opts.ToolboxOpts)
bar1.render('评论者Top10城市分布条形图.html')
柱形图的展示不是很直观也不全面,在含有地理位置的数据中,我们常采用采用地图的形式,为大家更加直观的进行展示,选取了观影城市最多的前三十个城市作为动态展示,如下图所示:
代码实现:
city_num = df_all.城市处理.value_counts[:30]
city_num.drop('国外', inplace=True)
city_num.drop('未知', inplace=True)
c1 = Geo(init_opts=opts.InitOpts(width='1350px', height='750px'))
c1.add_schema(maptype='china')
c1.add('geo', [list(z) for z in zip(city_num.index, city_num.values.astype('str'))], type_=ChartType.EFFECT_SCATTER)
c1.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c1.set_global_opts(visualmap_opts=opts.VisualMapOpts,
title_opts=opts.TitleOpts(title='评论者城市分布'),
toolbox_opts=opts.ToolboxOpts)
c1.render('评论者城市分布地图.html')
评分词云图
从词云图中可以看出,"喜剧" "和解" "母子" "笑点" "亲情"等词占较大的比重。骨子里还是囧系列那种公路喜剧片,这次用母子关系制造一系列的笑点,让电影的主题表达更进一步。但也有很多观众反映电影强行煽情,强行上升高度,强行搞笑,强行接续剧情,强行中年婚姻危机。
代码实现:
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType, ThemeType
word = WordCloud(init_opts=opts.InitOpts(width='1350px', height='750px'))
word.add("", [*zip(key_words.words, key_words.num)], word_size_range=[20, 200])
word.set_global_opts(title_opts=opts.TitleOpts(title="囧妈电影评论词云图"),
toolbox_opts=opts.ToolboxOpts)
word.render('囧妈电影评论词云图.html')
在热门评论里,用户阿暖说道:
“ 很平庸,很无趣,既不好笑,对于原生家庭的探讨也只是隔靴搔痒而已。”
竟然获得了5560个赞同。
同时C君也查了一下:
2010年《人在囧途》,豆瓣7.7分。主演是徐峥,导演叶伟民。
2012年《人在囧途之泰囧》,豆瓣7.4分,徐峥自导自演。
2015年《港囧》,豆瓣5.7分,徐峥自导自演。
2018年《我不是药神》,豆瓣9.0分,主演是徐峥,导演是文牧野。
2020年《囧妈》,豆瓣5.9分,徐峥自导自演。
所以徐峥一定是个好演员,但导演嘛,就不好说了。
有人说这次徐峥这个玩法是要做中国版的Netflix。Netflix 现在大家都知道是世界数一数二流媒体平台,就是视频网站,也能在电视上看。所以从口碑上看,《囧妈》只能算在形式上开了个头,就像当年徐峥是开启了中国电影的大票房时代,但真正的票房王是吴京,让我们期待一下吧。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;



















 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330