逻辑回归、决策树、支持向量机算法三巨头
1 逻辑回归
首先逻辑回归是线性回归衍生过来的,假设在二维空间上,本质上还是一条线,那么在三维空间,他就是一个平面。把数据分成两边,就是直的不能再直的一条线或者一个平面。那么假设现在我们有两个变量,就是图中这两个变量,为什么假设y=1是坏客户的话,根据图中可以看到,单个变量的划分并不可以把两种类型的客户分的很好,要两个变量相互作用,假设x1为查询次数,x2为在还贷款笔数,那可以看到当x1小以及x2比较小的时候,那么客户肯定在左下角的地方,那么当他其中一项比较高的时候就会趋于右上角,x1
x2都高的时候,就是越过分割线,落于分割线的上方了。这里我们可以看到,x1 x2是两个有趋势性的变量才可以达到这种这么好的一个分类效果。

那么现在假设数据是以下这种:

可以看到变量的趋势跟y的分类没有什么关系的时候,这时候逻辑回归就显得很鸡肋,分的效果一点都不好。
2 决策树
决策树。刚才说的是逻辑回归是一条直到不能再直的直线或者平面,那么决策树就是一条会拐弯,但是不能有角度的,永远直行或者90度拐的直线或者面,看下图,你可以理解为决策树就是一条贪吃蛇,他的目标就是把好坏客户分的很清晰明了,要是贪吃蛇过分的贪吃就会造成过拟合,那么过拟合是啥,就是你问你喜欢的妹纸,妹纸你喜欢什么样的男生,妹纸说,我喜欢长的好看的,帅气,温柔体贴,会做饭的,巴拉巴拉一大堆,足足100多条,然后你实在太喜欢妹纸,所以按照她的要求,到头来你真的跟妹纸在一起了,妹纸说,其实我只要你长得好看就可以了,其他的100多条都是无所谓的。拉回来决策树,决策树适应的数据假设像逻辑回归那种数据的话,其实按照决策树的这种贪吃蛇的方式其实还是很难分的,所以决策树适用的数据是变量与因变量呈现一个u型分布的数据,就是两头是一类,单峰聚集了另外一类数据。你在变量特征分析的,看到变量都是呈现这种趋势的,你就要暗喜了,老子要用决策树立功了!!!

3 支持向量机
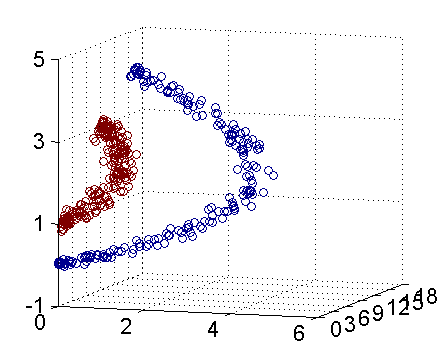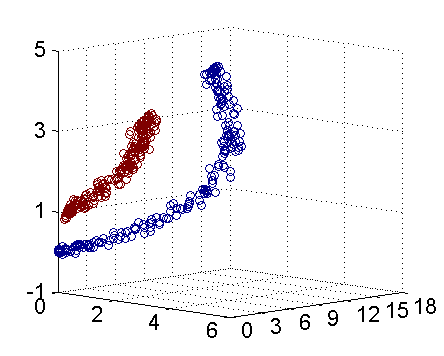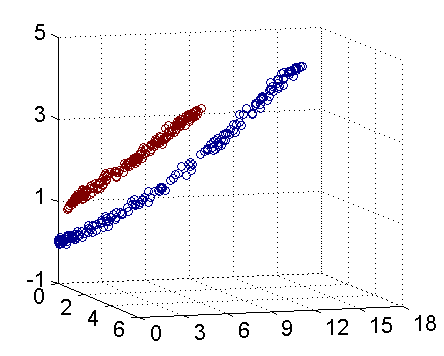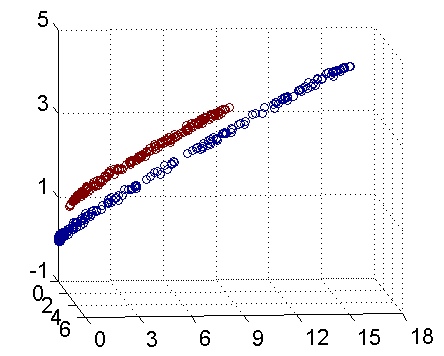
支持向量机,要是没有数学基础的人看支持向量机的把低维的数据转化成高维可以在高维空间分类的算法这句话时候估计是一脸懵逼,我以前也是很懵逼,这到底是啥,我们以只有两个变量的举个例子,譬如你现在相区分一群客户的好坏,这时候就给出这群人的两个变量,查询次数和贷款次数,然后这时候你通过某些什么开方啊,幂次数,取对数的方式啊,你刚好拟合除了三元方程,这条方程你把身高体重的数据输进去,算出来的第三个未知数在这条方程里面的,就是男的,在这方程里面就算女的,这样子可能你不是很清楚,请看下图

刚才我们把数据丢进入,支持向量机帮我们这份数据拟合了这个圆,把这两类数据分的像图中的这样子很好,那么这时候我们需要这条圆的方程,产生变量的运用口径,这条方程是:
25=(x-5)2+(y-5)2
那么这时候当贷款次数和查询次数分别减5再2次幂的时候如果数小于25那么就是好客户,假设大于25就是坏客户。支持向量机是在除了变量所有的维度之外又给了他一个维度之后,把拟合的方程再投放在原来的维度空间。支持向量机可以适用的数据那么就是在你用决策树和逻辑回归走投无路的时候就可以用支持向量机了,但是就像我们刚才得出这道方程一样,出来的变量口径是没有逻辑的,他可能要变量开方,取对数,假设你这模型要跟业务去解释的时候,我就不知道你要想多少套路了。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330