我们用大数据画了个圈,发现了城市的新边界
“首都北京,行政面积1.64万平方公里。”
“多大?”
“1.64万平方公里。”
“那是多大?”
比起行政面积,也许出行半径更能描述市民日常实际活动范围。滴滴媒体研究院利用滴滴出行平台订单数据对全国主要城市的出行半径进行“测量”,从一个侧面反映城市究竟有“多大”。
毫不意外的,北京的出行半径最大,31.7公里。也就是说,北京90%的出行订单的起点或终点在距离市中心(天安门)31.7公里的范围内,而从天安门开车到东六环,刚好是30公里。中国城市中,出行半径大于30公里的有4个:北京、上海、深圳和佛山。
全国主要城市出行半径排行
注:“出行半径”:若超过90%的出行起点或终点与城市中心的距离在R公里范围内,则定义城市半径为R(单位:公里),即大多数出行活动的起终点都在城市半径R范围内。

工作在北京东四环外传媒产业园的张扬,两年前把房子买在了南六环,每天开车上班单程需要近一个半小时。
上海的姗姗在市中心的一家日企工作,家住长宁区的她每天要乘地铁上下班,单程三站地,加上走路全程需要近40分钟。
一个城市有多大?看看上班族上下班要花的时间。这是衡量“城市有多大”的另一个维度:通勤。
如上所述的出行半径是一个静态的直线距离,它并不能体现出城市形态、城市规划、拥堵状况等因素。而平均通勤距离和时间则可以帮助我们融合更多的路面信息和生活体验,从而更好地感知一个城市到底有多大。
全国主要城市通勤距离&时间
**“通勤距离&通勤时间”:此处是指根据滴滴出行平台上打车出行数据测算的上下班通勤距离和时间,即工作日06:00-10:00和16:00-21:00期间通过滴滴顺风车和专快车来往于住宅小区和商务楼宇的订单的平均距离及时间,数据统计周期为2017年11月。
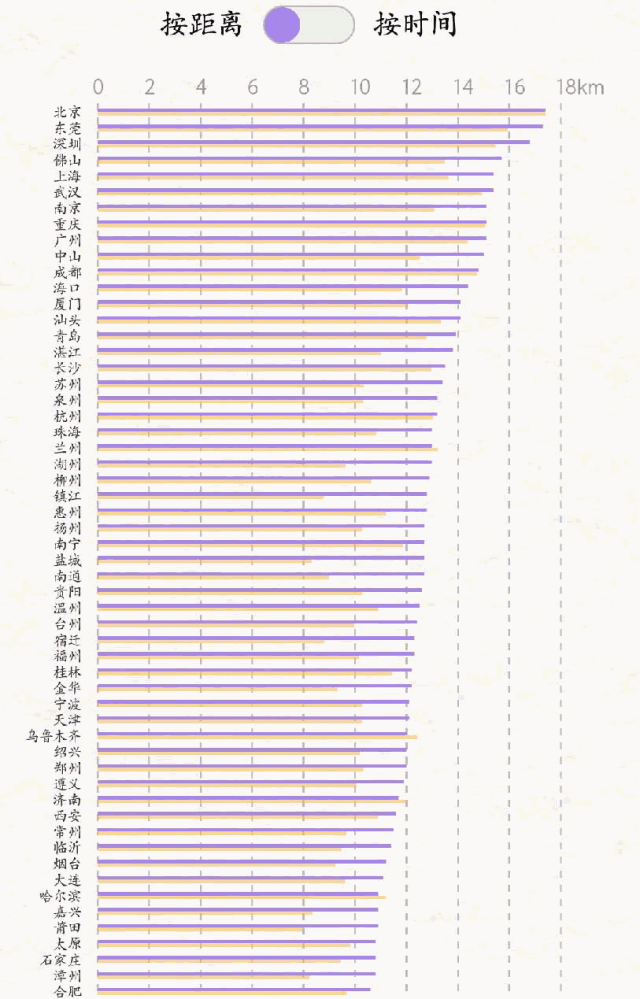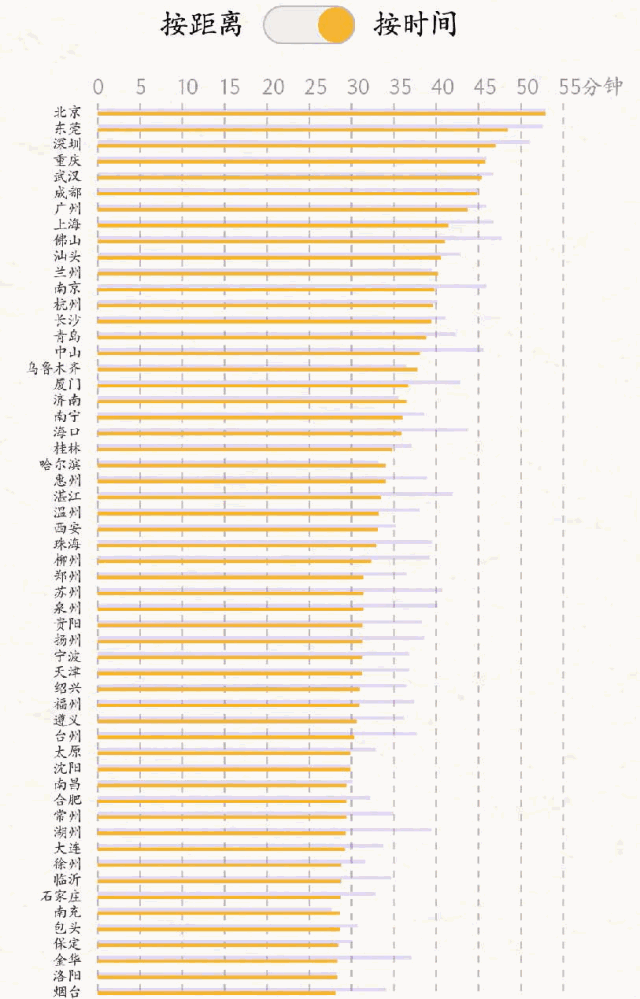
令人惊讶的是,广东东莞的平均通勤距离和时间分别为17.3公里和48.5分钟,超过了上海、广州、深圳这些一线城市,仅次于北京。早高峰期间,从东莞住宅区发出的订单中很大一部分会进入了深圳、广州、惠州等周边城市。这便不难理解,为何出行半径并不显著的东莞,会在通勤排行上如此高位。
出行半径、通勤距离&时间前十位

东莞北接广州,南连深圳,毗邻香港,是粤港澳大湾区的重要组成部分,据媒体报道,在东莞凤岗停满大量的粤B牌轿车,早高峰期间人流也几乎全部涌向深圳方向,珠三角一体化程度高,城市间连通性也极高,因而,在地域上仅用“行政区域”来描述生活区域便不够准确,这便引出另一个概念,“城市功能地域”。
四大城市功能地域
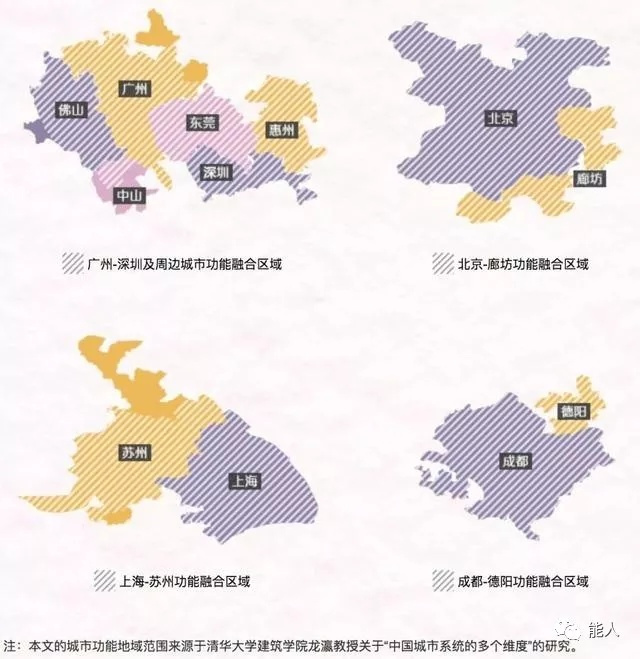
城市功能地域,是以24小时为周期的城市工作、居住、教育、商业、娱乐、医疗等功能所波及的范围。它或大于,也或小于本来的城市行政区域,由于如今城市群一体化进程不断加快,一个城市的功能区也很可能与相邻城市连成一片。
上图中呈现的功能地域是中国融合程度最高的四大城市群,以区域一为例,也许你生活在东莞,但每日的工作、娱乐范围,完全可能涵盖深圳、广州等城市。由此可见,在一定程度上,城市功能地域要比城市行政区更能准确描述你在这个城市可能的生活范围。
此时,让我们再回头考虑那个初始问题:“这个城市到底有多大?”,我们便有了一些更加贴合日常生活的数据:出行半径、通勤时间、通勤距离,以及城市功能地域。

CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330