作者:俊欣
来源:关于数据分析与可视化
也就在前天,南太平洋岛国汤加发生火山喷发,有专门的专家学者分析,这可能是30年来全球规模最大的一次海底火山喷发,它引发的海啸以及火山灰将对周边的大气、洋流、淡水、农业以及民众健康等都造成不同程度的影响。
今天小编就用Python当中的folium模块以及其他的可视化库来对全球的火山情况做一个分析。
准备工作
和以往一样,我们先导入需要数据分析过程当中需要用到的模块并且读取数据集,本次的数据集来自由kaggle网站,主要由美国著名的史密森学会整理所得
import pandas as pd import folium.plugins as plugins import folium
df_volcano = pd.read_csv("volcano.csv")
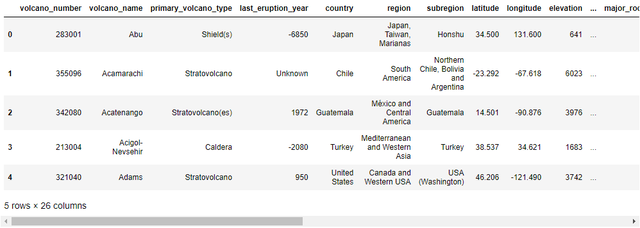
df_volcano.head()
output
数据集包含了这些个数据
df_volcano.columns
output
Index(['volcano_number', 'volcano_name', 'primary_volcano_type', 'last_eruption_year', 'country', 'region', 'subregion', 'latitude', 'longitude', 'elevation', 'tectonic_settings', 'evidence_category', 'major_rock_1', 'major_rock_2', 'major_rock_3', 'major_rock_4', 'major_rock_5', 'minor_rock_1', 'minor_rock_2', 'minor_rock_3', 'minor_rock_4', 'minor_rock_5', 'population_within_5_km', 'population_within_10_km', 'population_within_30_km', 'population_within_100_km'],
dtype='object')
全球火山带的分布可视化
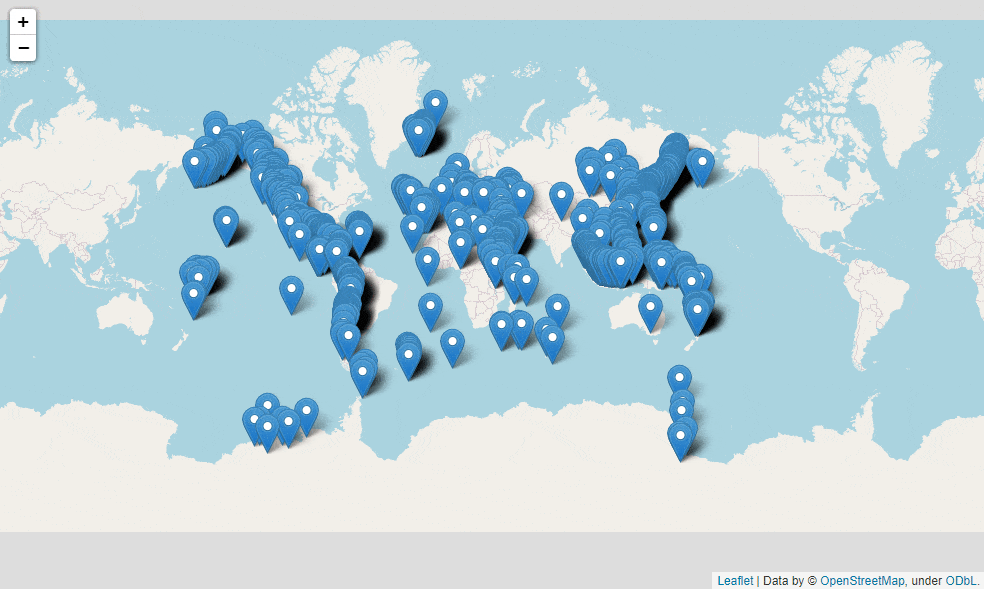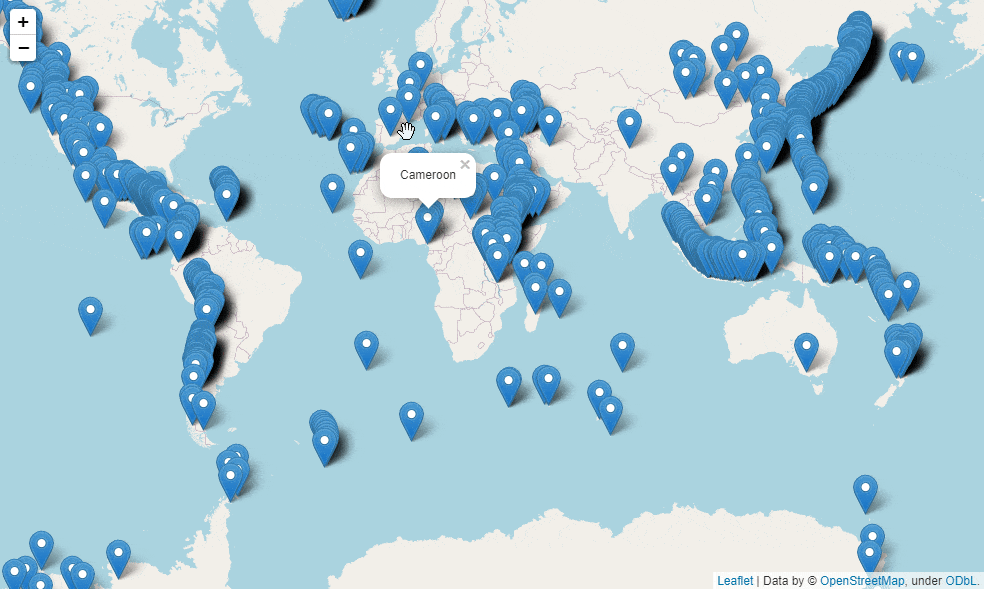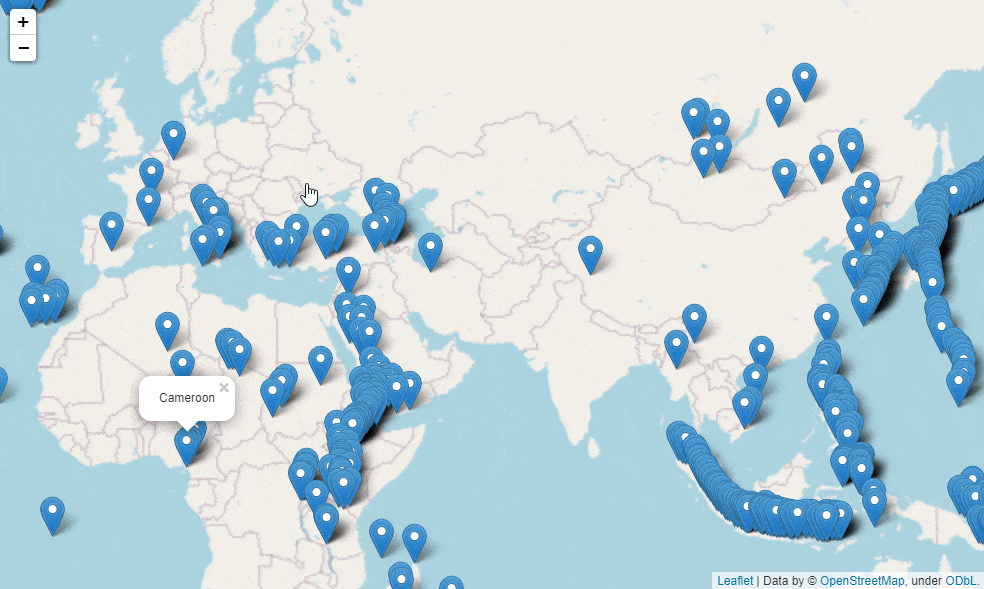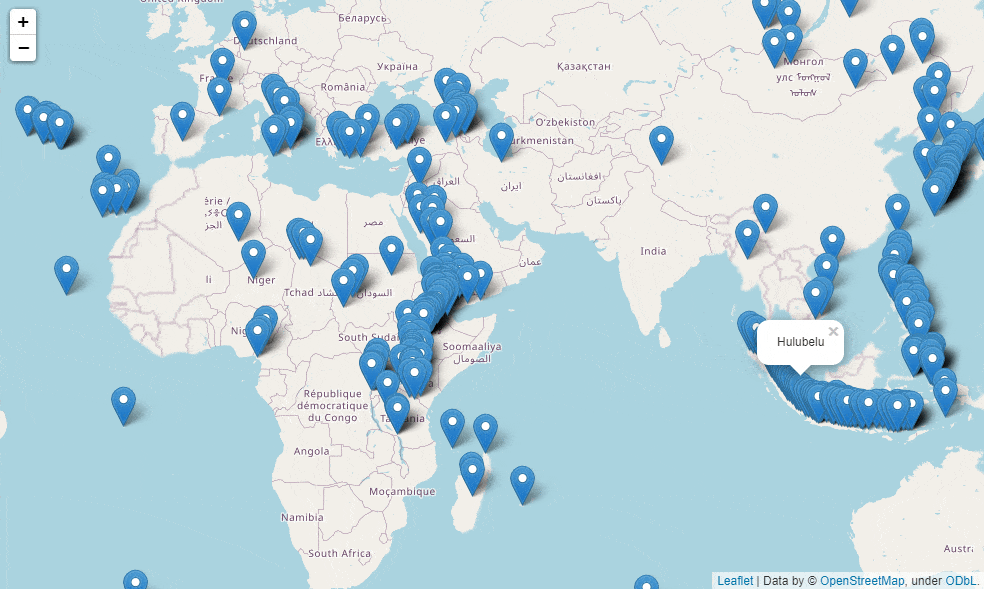
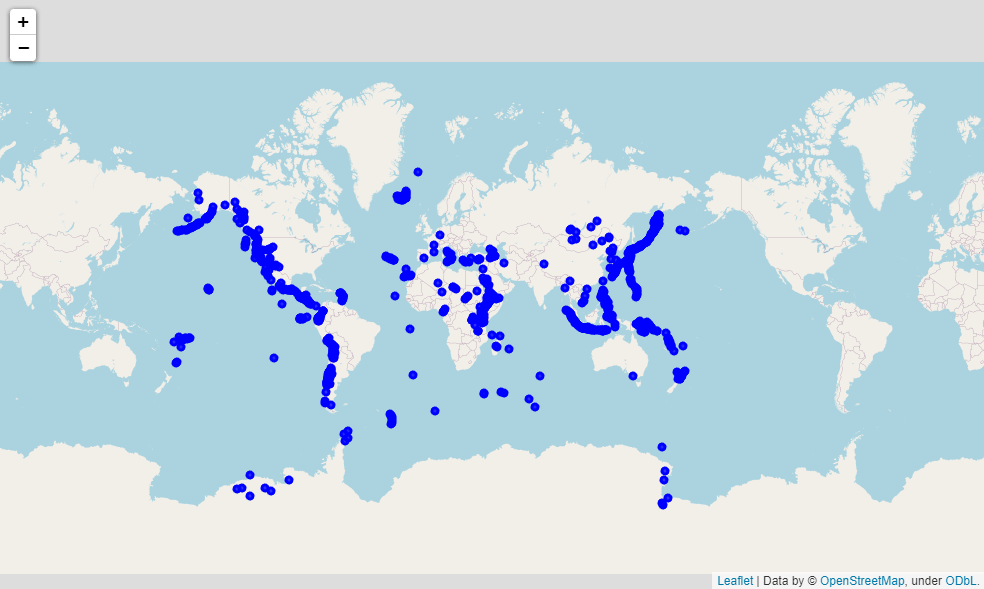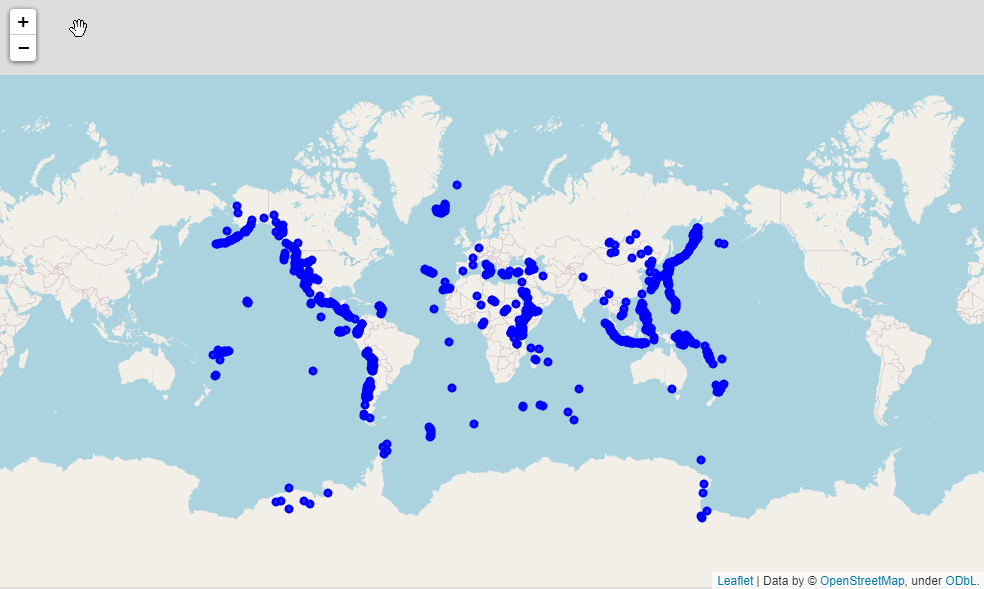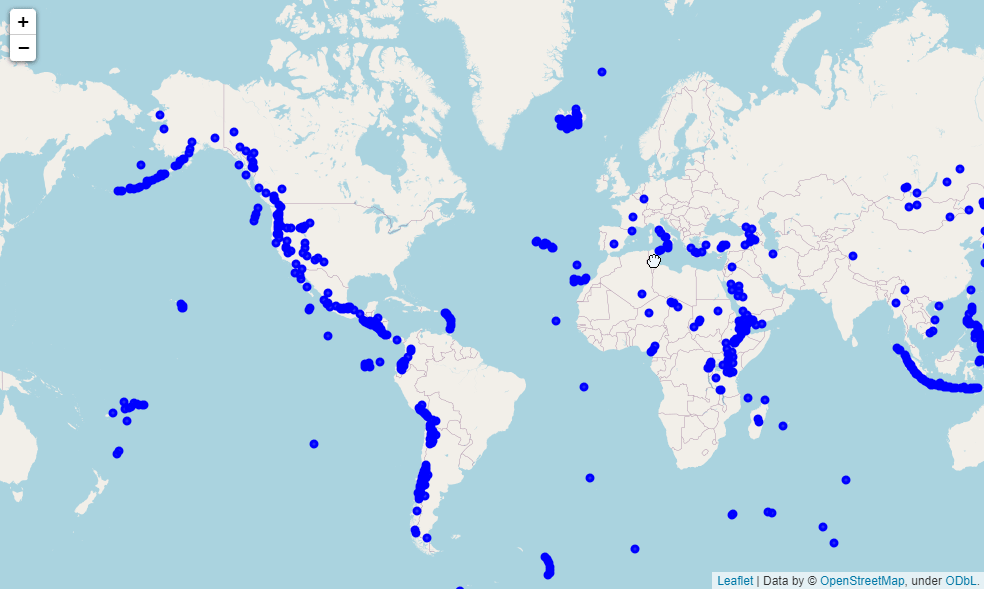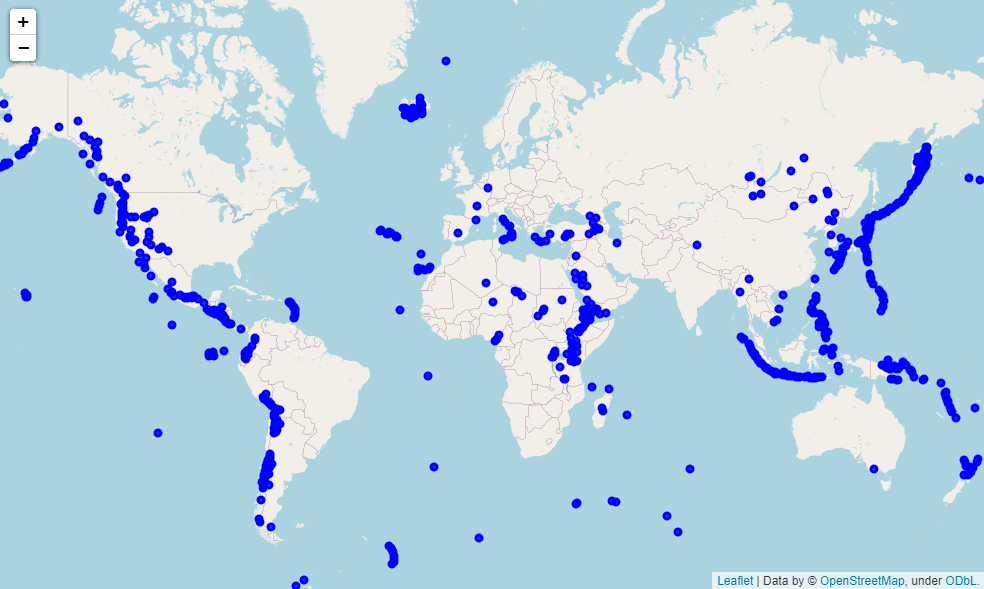
我们通过调用folium模块来绘制一下全球各个火山的分布,代码如下
volcano_map = folium.Map() # 将每一行火山的数据添加进来 for i in range(0, df_volcano.shape[0]):
volcano = df_volcano.iloc[i]
folium.Marker([volcano['latitude'], volcano['longitude']], popup=volcano['volcano_name']).add_to(volcano_map)
volcano_map
output
上述代码的逻辑大致来看就是先实例化一个Map()对象,然后遍历每一行的数据,主要针对的是数据集当中的经纬度数据,并且在地图上打上标签,我们点击每一个标签都会自动弹出对应的火山的名称
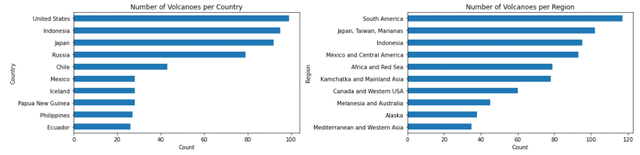
当然出来的可视化结果不怎么美观,我们先通过简单的直方图来看一下全球火山的分布情况,代码如下
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 4))
volcano_country = pd.DataFrame(df_volcano.groupby(['country']).size()).sort_values(0, ascending=True)
volcano_country.columns = ['Count']
volcano_country.tail(10).plot(kind='barh', legend=False, ax=ax1)
ax1.set_title('Number of Volcanoes per Country')
ax1.set_ylabel('Country')
ax1.set_xlabel('Count')
volcano_region = pd.DataFrame(df_volcano.groupby(['region']).size()).sort_values(0, ascending=True)
volcano_region.columns = ['Count']
volcano_region.tail(10).plot(kind='barh', legend=False, ax=ax2)
ax2.set_title('Number of Volcanoes per Region')
ax2.set_ylabel('Region')
ax2.set_xlabel('Count')
plt.tight_layout()
plt.show()
output
可以看到火山主要集中在美国、印度尼西亚以及日本较多,而单从地域来看,南美以及日本、中国台湾和印度尼西亚等地存在着较多的火山
全球火山带的分布可视化优化
接下来我们来优化一下之前绘制的全球火山分布的地图,调用folium模块当中CircleMarker方法,并且设定好标记的颜色与大小
volcano_map = folium.Map(zoom_start=10)
groups = folium.FeatureGroup('') # 将每一行火山的数据添加进来 for i in range(0, df_volcano.shape[0]):
volcano = df_volcano.iloc[i]
groups.add_child(folium.CircleMarker([volcano['latitude'], volcano['longitude']],
popup=volcano['volcano_name'], radius=3, color='blue',
fill=True, fill_color='blue',fill_opacity=0.8))
volcano_map.add_child(groups)
volcano_map.add_child(folium.LatLngPopup())
output
地图可视化实战
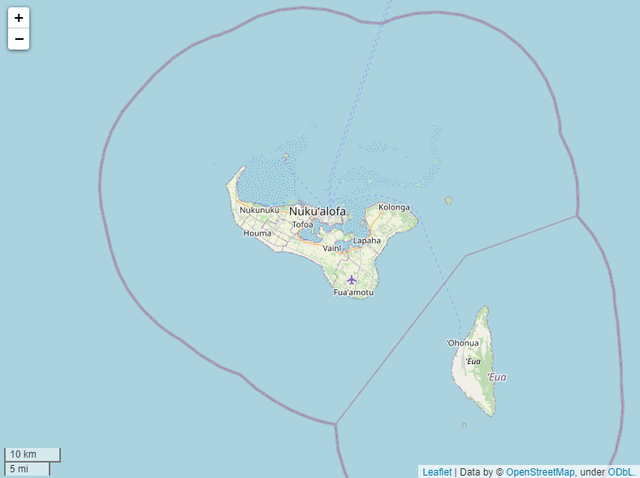
然后我们来看一下这次火山的爆发地点,汤加共和国位于西南太平洋,属于大洋洲,具体位置是在西经175°和南纬20°左右,
import folium.plugins as plugins import folium m = folium.Map([-21.178986, -175.198242], zoom_start=10, control_scale=True, width='80%') m
output
第一个参数非常明显代表的是经纬度,而zoom_start参数代表的是缩放的程度,要是我们需要进一步放大绘制的图表,可以通过调整这个参数来实现,而width参数代表的则是最后图表绘制出来的宽度。
在地图上打上标记
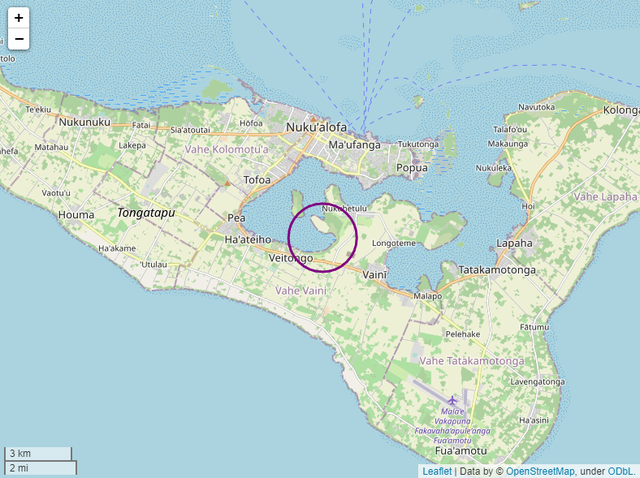
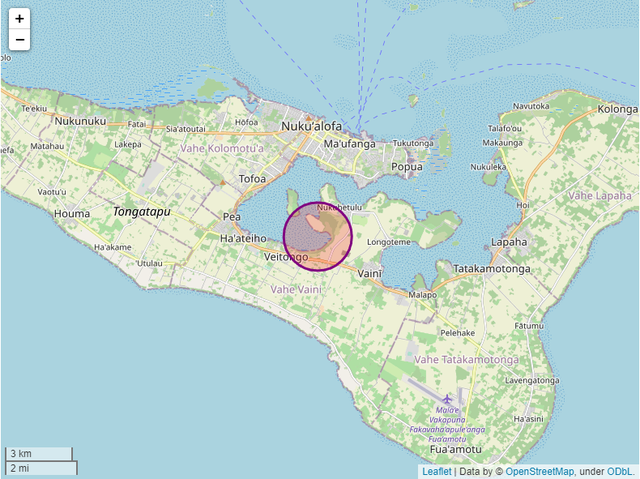
我们也可以在绘制出来的地图上面打上标记,例如画个圆圈,代码如下
m = folium.Map([-21.178986, -175.198242], zoom_start=12, control_scale=True, width='80%') folium.Circle(location = [-21.177986, -175.199242], radius = 1500, color = "purple").add_to(m) m
output
或者给圈出来的区域标上颜色,代码如下
m = folium.Map([-21.178986, -175.198242],
zoom_start=12,
control_scale=True, width='80%')
folium.Circle(location = [-21.177986, -175.199242], radius = 1500,
color = "purple", fill = True, fill_color = "red").add_to(m)
m
output
深远影响
本次汤加火山爆发的VEI强度为5-6级,属于本世纪以来最强等级,后面连带引发的海啸影响了太平洋沿岸地区。太平洋沿岸的智利、日本等国的潮位站监测到30厘米至150厘米的海啸波,我国潮位站最大海啸波幅在20厘米以下,短期内太平洋沿岸国际航运或受到影响,需要重点关注美豆到港情况。
而从长期来看,热带火山爆发或提高全球极端天气发生概率,从而影响农作物的生长,对整个农产品的供应造成深远的影响,而如果火山灰大面积扩散,或进一步影响全球航空业,降低运输效率,拖累全球供应链。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;














 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330