“大数据”思维在公安实战中的思考和实践_数据分析师考试
近年来,伴随着全国各地公安机关信息化的迅猛发展,数据共享和深化应用的需求空前高涨。但是,随着数据的汇聚和数据量的爆炸式增长,传统的数据库和数据仓库技术出现了诸多瓶颈问题,特别是对于 PB 级的非结构化数据处理以及多维度关联分析、数据挖掘、情报研判等需求,传统的数据存储和处理方式都面临着效率低、成本高、可靠性差、扩展能力不足等不可逾越的障碍。以搭建“大数据”处理和分析平台为突破口,寻求公安信息化应用新的效益增长点,已经成为公安机关信息化应用的热点问题。本文以两个案例的形式,分析了公安机关在“大数据”方面开展的一些新的实战应用和新的思维方法,以期供广大同行借鉴和参考。
案例一:电子警察疑似套牌车自动识别系统
(1)实例目标
这个实例目标是在近 12 亿“电子警察”(卡口视频抓拍系统) 抓拍车牌数据中查找出套牌车辆,可称为“疑似套牌车模型”。和通用的数据挖掘方法一样,对于大数据的处理原则也是“以业务规则为核心,以数据资源为基础,以运算能力为支撑”。这个实例是在 2011 年初启动的,大约经过了半年多的研发和应用探讨,取得了一定的应用实效。
(2) 操作流程
第一步,业务规则制定。这个实例的业务排查规则是: 在一个较短的时间段内,同一车牌不可能被不同路口“电子警察”抓拍设备抓拍到。这其中涉及到三个变量,一个是时间,第二个是车牌,第三个是“电子警察”的地理位置。在与交警部门进行了业务规则研究后,最终确定的数量是:在 5 分钟之内,如果在距离大于 10 公里的“电子警察”同时抓拍到同一个车牌,这个车牌可能就是套牌,因为车速一般不能超过 120 公里/小时。另外,以“电子警察”位置经纬度测算其直线距离,比一般道路实际距离要短。
第二步,数据准备。如果面对的是千万级的数据,常规 SQL 查询语句就可以解决这个问题。数据量如果再大,采用分区表的形式一般也可以解决这个问题。但是,此实例中,遇到的第一个数据是车辆抓拍数据。数据量是 3 年“电子警察”抓拍的数据总和,目前南通的抓拍量大约是一天 800 万左右,最后 3 年的数据汇聚到 12 亿左右。因此,这个实例的总体技术框架可以用“HADOOP + ORACLE”来描述亿级以上的数据。这里指的是数据条数,因为针对的都是结构化的数据,笔者认为,先把结构化数据的海量数据处理到位,然后再开始启动半结构化、非结构化的大数据研究。亿级以上的数据用分布式的 HADOOP 来直接处理,或者称为预处理,可处理至千万级或者百万级数据,然后再依托传统的 ORACLE 来处理。第二个数据是“电子警察”的地理位置数据,可以从 PGIS 取得支撑,取得全市“电子警察”的经纬度信息。将本市所有“电子警察”卡口的坐标位置建立辅助表,如表 1 所示。记录每个卡口的经纬度,为计算不同卡口之间的距离准备。最后,还有一个重要的数据———时间。全市“电子警察”抓拍设备必须进行统一授时,否则这个亿级以上的数据模型就失去了意义。


第三步,利用 HADOOP 计算。这是最关键的一步,将 12 亿“电子警察”抓拍车牌数据,利用分块的模式,分别存储到 10 台普通 PC 服务器集群的 HADOOP 分布式存储环境中。每个块存储 300 万数据,分 380 个块存储在 9 台数据节点中,共占用存储空间 103 G。在数据传输交换上,使用分布式索引创建工具,经过 3 小时 10 分钟将数据从不同的oralce 数据库存储到 HDFS 分布式存储环境中,见图1 所示。
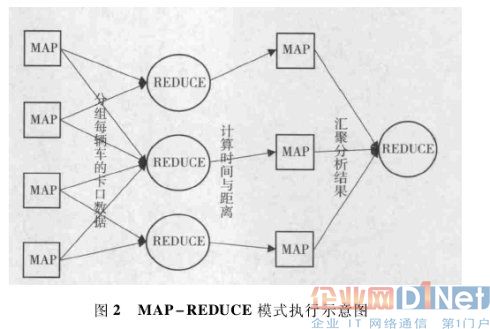
而后,采用 HADOOP 的 MAP -REDUCE 模型,对分块数据分别进行运算,首先使用 MAP 对每个车在卡口的时间进行分组,MAP 执行结束后,使用REDUCE 对各个块的数据按照车牌号进行汇总,再使用 MAP 对每个车在卡口出现的时间与不同卡口之间的距离进行运算,对于在小于 5 分钟内,在距离大于 10 公里的卡口同时出现的车辆,认定为疑似套牌车。最后使用 REDUCE 将统计结果汇总。其具体执行过程见图 2 所示。
第四步,结果。这个运算模型在 10 台 PC 服务器组成的 HADOOP 集群中,以 40 个初始 MAP 进行分布式执行,经过约 50 分钟执行完毕,共排查出394 辆疑似套牌车牌。这个效率已经基本能够满足应用要求
( 3) 结果应用。
(人工辅助)技术部门和交警部门共同研究分析了上述结果,发现在这 394 辆车里,有约三分之二( 也就是 250 辆左右) 是因为自动识别系统的误判造成的错误信息( 如 B 和 8、D 和 0 容易出现误判) ,这说明公安机关抓拍设备的识别率还要提升。在余下的约 150 辆车中,已经在控的约有 60 辆,其他 90 余辆车通过人工辨别、研判,确认为新发现的套牌车,现已全部纳入了套牌车布控查缉系统开展后续工作。
案例二:违法犯罪人员入住宾馆规律
实例目标:分析 10 年以来在押的违法犯罪人员曾入住旅馆的规律,为治安防控核查工作提供指导。
通过多方努力,我们汇聚到 10 年的旅馆数据约5 亿余条,10 年内本地在押的人员数据约 65 万条。利用计算机集群,首先建立了比对模型,根据 HADOOP开展比对来组织数据,将 65 万条人员数据放到 5 亿条住宿数据中去找相同项。以“1O + 1”的模式,即10 台服务器作数据节点,1 台作为控制节点,“跑”一遍的时间是 50 分钟左右。最后得到 10 年间在押的人员曾经入住旅馆数据约72. 1 万条。
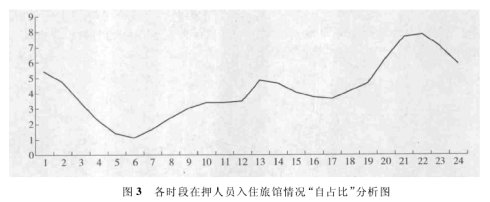
( 1) 全部在押人员各时段入住旅馆情况的占比分析,具体情况见图 3。
这是一种比较常规的分析方式。面对 70 万的小数据,从 10 年全部在押人员自身入住情况对比,可称为“自占比”分析。从上图 3 可以看出,在押人员入住“自占比”的第一峰值在 22 时左右,第二峰值在 13 时左右,谷值在 6 时左右。这说明,按照 10年来积累的数据看,我们关注嫌疑对象入住旅馆的重点时段应该是夜间 10 时左右和下午 1时左右。
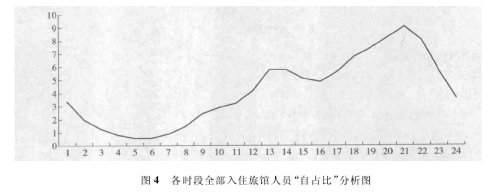
( 2) 针对全部入住旅馆人员各时段占比分析,具体情况见图4
根据 10 年来全部数据量的规模,传统的关系型数据库处理这些数据效率会很低。用 HADOOP 的MAP -REDUCE 计算框架,15 分钟左右全部完成计算工作,得出图 4 中的结果,可与第一项在押人员入住规律作比较。通过对比可以明显看出,在押人员入住“自占比”趋势与全部人员入住占比的趋势基本一致。这说明在 21 时和下午 1 时左右,本身也是正常人员入住旅馆的高峰时间。因此,这项分析虽有意义,但是针对实战的指导性分析还需要进一步研究。
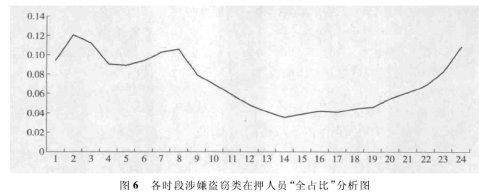
( 3) 各时段在押入住旅馆人员与该时段全部正常入住人员的占比分析。
如果把上面的比较分析方式称为关注对象的“自占比”,那还有另一种比较方式,即关注对象与全部对象之间的比较,我们可称为“全占比”。各时段在押人员入住旅馆的“全占比”情况见图 所示。
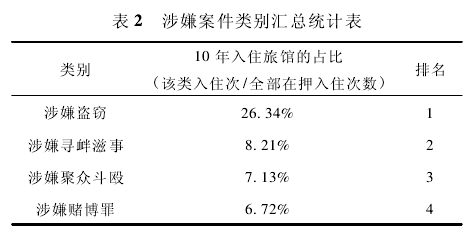
进一步思考通过上述两个案例分析,我们不难发现,基于’大数据#统计分析相关规律的业务建模,可能会逐步超越目前的行业经验,发现事物本质的新的联系,颠覆一些传统的行业规则$因此,迎接’大数据#时代的到来最需要的是一种全新的思维方法。
大数据思维是一个不断演进的过程
两个实例代表了对’大数据#处理与应用的一个演进过程。在起步阶段,我们受到’小数据”思维的惯性控制,增加计算能力的直接目的就是为了提高精确性,总希望直接找到违法犯罪分子。但因为数据量庞大,传统的技术效率低,不能完成海量数据处理任务了,因此想到了分布式计算,并取得了一些应用成效。
在第二个案例中,我们进一步发现,大数据分析中的精确查询之外,还有更广泛应用的更重要的趋势分析和宏观研判。大数据处理更能体现的是一种群体行为,通过海量的数据去发现一个隐藏在数据背后的客观事实,公安大数据要更加重视通过各种工具与方法,通过海量数据的分析发现大数据中隐含的知识和关系。这种’大数据#的思路决定了我们今后的出路! 规律分析是未来一个时期公安’大数据#应用的重点从上述实例中可以看出,引用的数据并不是非常庞大,分析方式是比较简单的比对方法,展示方式也是用较直接和较单一的折线图,仅此就能挖掘出服务实战的结果,这是传统的数据处理方式无法实现的$这就是’大数据#思维产生的作用。
在’小数据#时代,由于掌握的数据量不够多,范围不够全,因此我们的决策更依赖直觉和经验,对事物规律性的把握往往需要一个很漫长的积累过程,而且也容易遗漏。但是,随着’大数据#时代的来临,丰富的多维度数据应用使得公安传统的业务思路得到了极大的丰富,大数据破题的真正关键,在于领会贯通大数据的思维方式。
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330