ABtest做的好,产品优化效果差不了!可见ABtest在评估优化策略的效果方面地位还是很高的,那么如何在业务中应用ABtest? 结合企业实际场景,给大家整理一套详细的应用流程。
一、ABtest是啥?
AB测试是互联网行业在流量红利消退背景下实现精细化运营的核心工具。并且AB测试进阶为数据分析人员关键技能,以前Excel为主力,SQL为加分项;现在SQL成为基础,AB测试进阶为关键能力。
AB测试借鉴医学双盲实验原理,通过构建实验组/对照组、随机分配同质化用户、保证样本规模三大条件,验证产品改版的实际效果。在增量转存量的竞争格局中,巨型APP占据用户主要时长,新功能上线需通过分流测试精准捕捉用户偏好,避免主观认知偏差。
该方法通过统计验证功能改版对用户满意度、留存率等核心指标的影响,成为企业优化用户体验、提升存量价值的关键科学决策工具,标志着互联网行业从粗放增长转向数据驱动的精耕时代。
二、ABtest的局限性
基于ABtest的核心原理,AB测试也不是万能的。核心在于是否有条件开展实验搜集数据。
AB测试适用场景
1、产品迭代
主要是界面、功能、流程优化,可在原基础上分流量验证效果。不确定新设计好不好?让一半用户用老版本,一半用新版,看哪个版本用户更喜欢、转化更高。
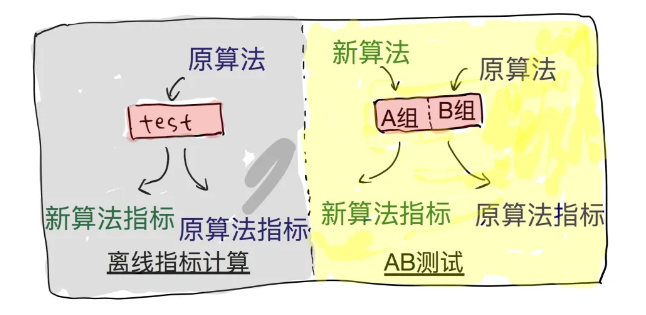
2、算法优化
通过分流对比算法模型效果。工程师开发了两种算法,同步上线对比:A组用旧算法,B组用新算法,看哪个能让用户刷得更久、点得更多。
3、营销策略
搞营销活动时,比如双11促销,不同广告文案哪个吸引人?早中晚哪个时段发短信效果好?针对白领还是学生推广更有效?分人群测试立马见分晓。
AB测试不适用场景
变量不可控(如跨APP联动策略,外部干扰因素过多)。样本量不足,比如统计结果易失准,需基础数据支撑。全量投放的场景,如发布会、全局换LOGO等无法分割用户场景。
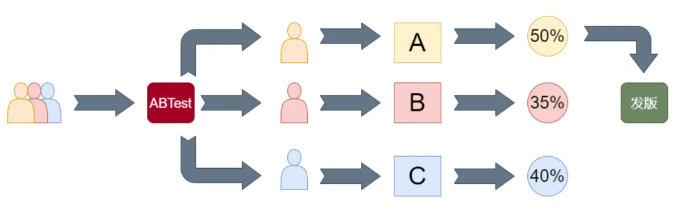
三、AB测试的实现
AB测试的基本流程我们可以总结为以下一张图:

细化下来的流程梳理:
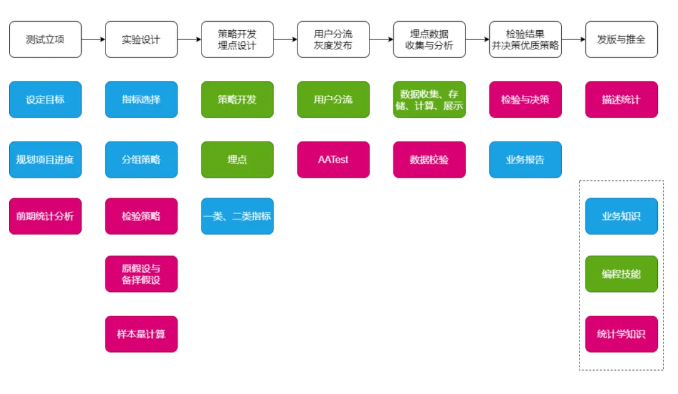
1、明确目标与假设
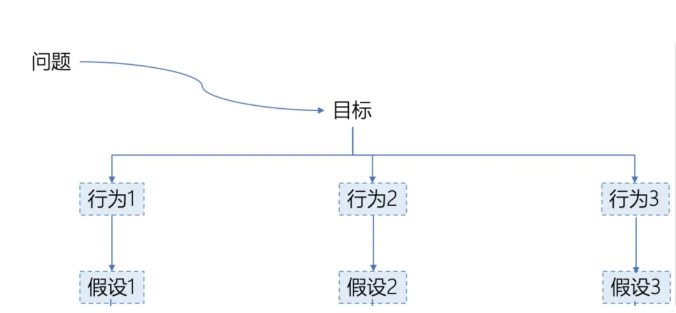
- 业务问题:确定要优化的核心指标,比如转化率、留存率、收入等。
- 假设构建:提出可验证的假设,例如:“调整按钮颜色可提升点击率”等
- 关键指标:选定核心指标,如点击率、订单完成率,辅助指标如用户停留时长等。
核心指标用来度量我们这次实验的效果,以及计算相应的样本量。辅助指标则用来度量,该实验对其他数据的影响。
2、实验设计
- 变量定义:确定实验组和对照组的差异(如UI改动、算法策略)。
- 样本量计算:基于统计功效(Power)、显著性水平(α)、预期效果(Effect Size)计算所需样本量。
- 实验周期:覆盖用户行为周期(如工作日+周末),避免短期波动影响。
3、实施与监控
- 数据埋点:确保关键行为(如按钮点击、订单提交)被准确记录。
- 异常监控:实时监控指标异常(如系统崩溃导致数据丢失)。

4、数据分析与决策
- 统计检验:使用T检验、Z检验或贝叶斯方法判断显著性。
- 结果解读:排除干扰因素(如节假日影响),综合业务价值判断是否全量。
- 若结果不显著,分析原因(样本不足、假设错误)并迭代新实验。
四、案例应用
我们以与大家生活相关的打车场景为例,看看出行平台如何运用ABtest来优化业务。
1、明确目标与假设
- 业务问题:比如产品经理通过调整优惠券发放策略(如优惠券面额、发放规则或补贴力度变化)来提升每日GMV。
- 假设构建:提出可验证的假设(例如:“通过调整优惠券发放策略,GMV没有提升”)。
- 关键指标:选定核心指标(GMV)和辅助指标(订单完成率、优惠券使用量、订单数量等)。
2、实验设计
- 变量定义:确定实验组和对照组的差异(优惠券发放策略差异)。
- 样本量计算:基于统计功效(Power)、显著性水平(α)、预期效果(Effect Size)计算所需样本量。
- 实验周期:覆盖用户行为周期(如工作日+周末),避免短期波动影响,实验周期一个月。
3、实施与监控
- 异常监控:实时监控指标异常(如系统崩溃导致数据丢失)。
4、数据分析与决策
- 指标对比:计算核心指标的提升幅度及置信区间。有时候要求不严格可以通过可视化来查看是否存在差异,严谨的话还需进行统计检验。
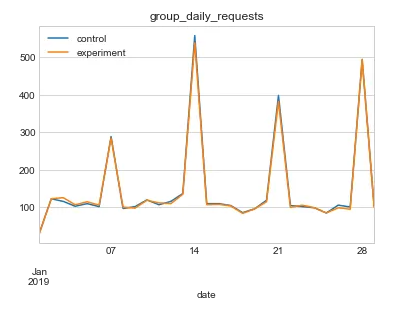
统计检验:使用T检验、Z检验或贝叶斯方法判断显著性。
由于样本个数为29(少于30)个,是小样本,差值服从t分布。满足配对样本T检验的条件**
- H0原假设: 实验组daily requests与控制组不存在差异
- H1备择假设: 实验组daily requests高于控制组
t,p_twotail = stats.ttest_rel(experiment_group.daily_requests, control_group.daily_requests)
print(f'假设检验的t值={t:.3f} p值={p_twotail:.5f}')
假设检验的t值=-1.472 p值=0.15227
- p>0.05,说明在95%显著水平下,t在统计上不显著的,也就是接受原假设。
- 结果解读:排除干扰因素,比如节假日影响,综合业务价值判断是否全量。实验组daily requests与控制组不存在差异,查找原因并迭代新实验。
避坑宝典
1、AB测试一定要从小流量逐渐放大
如果上线一个功能,直接流量开到50%去做测试,那么如果数据效果不好,或者功能意外出现bug,对线上用户将会造成极大的影响。所以,建议一开始从最小样本量开始实验,然后再逐渐扩大用户群体及实验样本量。
2、一定要在同一时间维度下做实验
举例:如果某一个app,周一到周五对A做了一个实验,周六周日对用户群B做了同一个实验,结果周末的效果明显较差,但是可能本身是由于周期性因素导致的。所以我们在实验时,一定要排除掉季节等因素。
3、如果多个实验同时进行,一定要对用户分层+分组
比如,在推荐算法修改的一个实验中,我们还上线了一个优惠券发放策略优化的实验,那么我们需要将用户划分为4个组:A、老算法+老策略,B、老算法+新策略,C、新算法+老策略,D、新算法+新策略,因为只有这样,我们才能同时进行的两个实验的参与改动的元素,做数据上的评估。
推荐学习书籍
《CDA一级教材》在线电子版正式上线CDA网校,10万+在读,适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。

免费加入阅读:https://edu.cda.cn/goods/show/3151?targetId=5147&preview=0
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330