在职场中,许多言辞并非表面意思那么简单,有时需要听懂背后的“潜台词”。尤其在数据分析的领域里,掌握常用术语就像掌握一门新语言的基础词汇,是理解数据、与同行有效沟通以及做出明智决策的关键。

一、战略与目标类
对齐:指不同团队或人员在目标、观点、行动等方面达成一致。例如 “我们需要和市场部对齐推广策略,确保活动的一致性”。其目的是为了避免各部门各自为政,保证公司整体战略方向的统一。
颗粒度:描述对事物细节的把控程度。颗粒度细意味着关注到更多细节,粗则表示只关注大致框架。比如 “这份报告的颗粒度太粗,需要细化到每个业务板块的具体数据”,强调对分析内容精细化程度的要求。

拉通:与 “对齐” 类似,强调打破部门壁垒,让各方信息、资源、行动等顺畅流通并达成一致。例如 “跨部门项目需要拉通各团队的进度,确保按时交付”,旨在促进团队协作,提高工作效率。
聚焦:将精力、资源集中在特定的业务或目标上。例如 “接下来我们要聚焦核心业务,提升产品的竞争力”,突出明确重点,避免资源分散。
二、业务执行类
落地:将计划、方案转化为实际行动并取得成果。比如 “这个创新的想法很好,但关键是要如何落地”,强调将理论或规划切实转化为实际操作。
抓手:指推动某件事情得以开展的关键着力点或切入点。例如 “提高用户活跃度是提升产品粘性的重要抓手”,表示通过这个关键因素来实现整体目标。
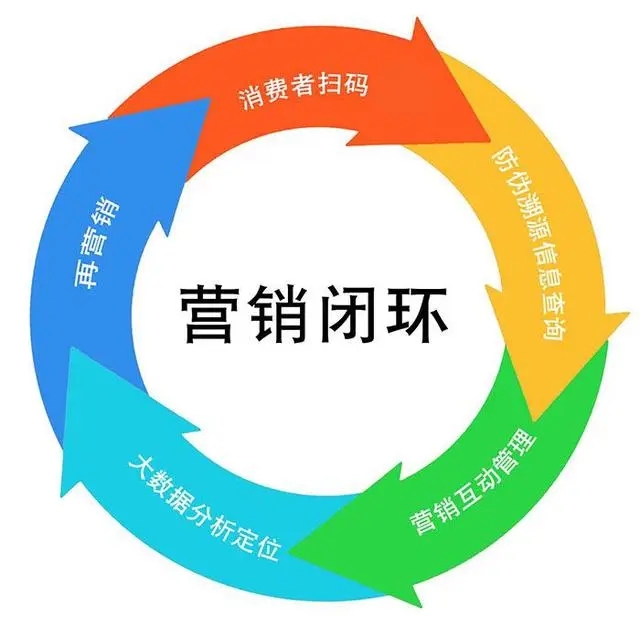
闭环:业务流程从起点到终点形成完整的回路,每个环节相互关联且能有效反馈和优化。如 “我们要打造一个营销闭环,从广告投放、用户转化到售后反馈都要紧密衔接”,确保整个业务流程的完整性和可持续性。
复盘:对已完成的项目、活动等进行回顾、分析和总结,从中吸取经验教训,以便未来改进。例如 “项目结束后,我们一起进行复盘,看看哪些地方可以做得更好”,这是互联网团队不断提升的重要方法。
三、数据分析常用术语
数值型数据:这类数据是由数字组成,用于表示数量或大小。又可细分为离散型和连续型。离散型数据取值是有限个或可列个值,比如一家店铺每天的订单数量,只能是整数。连续型数据则可以在一定区间内取任意值,像产品的重量、长度等。在分析销售数据时,销售额就是数值型数据,通过对其分析,能了解业务规模。
分类型数据:用于描述事物的类别或属性。例如,产品的类别(服装、电子产品、食品等)、客户的性别(男、女)。分析分类型数据可以帮助我们了解不同类别之间的差异,比如不同产品类别的销售占比,从而优化产品布局。
2.集中趋势度量
均值:也就是平均数,是一组数据的总和除以数据的个数。例如,一个班级学生的考试成绩均值,能反映班级整体的学习水平。但均值容易受极端值影响,比如班级里有个别学生成绩特别高或特别低,就会使均值偏离大部分学生的真实水平。
中位数:将一组数据按从小到大或从大到小的顺序排列后,位于中间位置的数值。如果数据个数是奇数,中位数就是中间的那个数;如果是偶数,中位数则是中间两个数的平均值。中位数不受极端值影响,在分析收入、房价等数据时,能更好地反映数据的中间水平。
众数:一组数据中出现次数最多的数值。在分析消费者对产品颜色的偏好时,众数就能告诉我们最受欢迎的颜色。
3.离散程度度量
极差:一组数据中的最大值减去最小值。它简单直观地反映了数据的波动范围。例如,某公司员工工资的极差,能让我们大致了解工资差距。但极差只考虑了最大值和最小值,对数据内部的离散情况反映不足。
方差:每个数据与均值之差的平方的平均值。方差越大,说明数据越分散;方差越小,数据越集中在均值周围。它全面考虑了所有数据的离散情况,但单位是原数据单位的平方,不太直观。
标准差:方差的算术平方根。它与原数据单位相同,更直观地衡量数据的离散程度。在质量控制中,通过计算产品尺寸的标准差来评估生产过程的稳定性。
4.数据分布
正态分布:也叫高斯分布,是一种常见的连续型概率分布,形状像钟形曲线。许多自然和社会现象的数据都近似服从正态分布,比如人的身高、智商等。在正态分布中,大部分数据集中在均值附近,离均值越远,数据出现的概率越低。了解数据是否服从正态分布,对选择合适的统计方法很重要。
偏态分布:数据分布不对称,分为正偏态(右偏)和负偏态(左偏)。正偏态分布中,数据的长尾在右侧,即较大值的一端;负偏态分布则相反,长尾在左侧。例如,一些产品的价格分布可能是正偏态,少数高价产品拉高了均值。
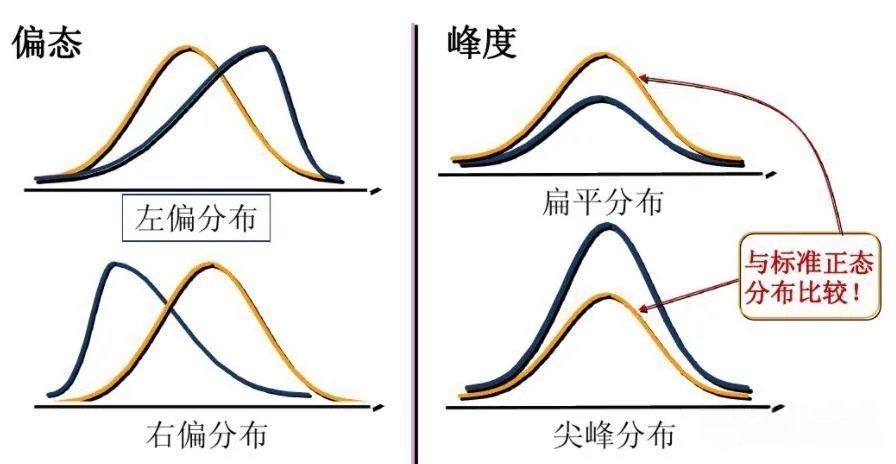
5.相关性与回归
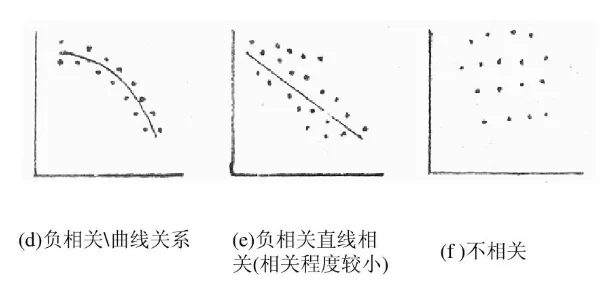
相关性:衡量两个变量之间线性关系的强度和方向。相关系数取值在 -1 到 1 之间。当相关系数为 1 时,两个变量完全正相关,即一个变量增加,另一个变量也按比例增加;为 -1 时,完全负相关;为 0 时,不存在线性相关关系。比如分析广告投入与产品销量的相关性,若呈正相关,说明广告投入可能对销量有促进作用,但要注意相关性不代表因果关系。
回归分析:通过建立数学模型来研究变量之间的关系,以预测因变量的值。常用的有线性回归,假设因变量与自变量之间存在线性关系。例如,根据房屋面积、房龄等自变量预测房价。回归分析能帮助我们理解变量之间的定量关系,为决策提供依据。
虽说互联网黑话在咱业内交流的时候,确实挺方便的,能简洁明了地表达很多复杂的事儿。但要是用得太猛了,也容易出问题,别人听着就跟听天书似的,根本不明白啥意思。

所以啊,大家得心里有数,跟不同的人说话,在不同的场合,得琢磨着怎么用这些词儿。能用得恰到好处,让信息又准又清楚地传达到位,这才是真本事。不然光顾着秀黑话,把沟通搞砸了,那可就得不偿失啦
抓住机遇,狠狠提升自己
随着各行各业进行数字化转型,数据分析能力已经成了职场的刚需能力,这也是这两年CDA数据分析师大火的原因。和领导提建议再说“我感觉”“我觉得”,自己都觉得心虚,如果说“数据分析发现……”,肯定更有说服力。想在职场精进一步还是要学习数据分析的,统计学、概率论、商业模型、SQL,Python还是要会一些,能让你工作效率提升不少。备考CDA数据分析师的过程就是个自我提升的过程。

CDA 考试官方报名入口:https://www.cdaglobal.com/pinggu.html











 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330