01 为什么要学这门课?
在当今数字化、信息化的时代背景下,数据扮演着越来越重要的角色。随着互联网和移动通信的快速发展,我们每天都产生大量的数据,其中包含了许多隐藏的商机和洞察力。
通信运营商经常面临一个问题,如何选定商圈才能最大化收益?这里就要用到数据挖掘算法,来进行处理,具体来说,使用某通信运营商提供的接口解析用户的定位数据以及对应属性,并对基站进行分群。通过比较不同商圈的分群结果,选择合适的区域进行后续的营销活动。
02 如何学这门课?
第一步,理解K均值聚类算法及其在项目中的应用。需要掌握相似度度量、算法逻辑和算法评估等方面的知识。
第二步,应该着重学习与项目相关的技术和操作。首先是数据可视化,需要学会使用适当的工具将数据以图形方式展示出来,以便更好地理解和分析数据。其次是数据清洗,需要了解如何处理数据中的缺失值、异常值和重复值,确保数据质量。此外,还应该学习相关性分析和维度归约技术,以减少数据的维度并提高模型的效果。
还需要学习K均值算法的调优策略,以进一步改进模型的性能。这包括选择合适的聚类数目、初始化方法和迭代停止条件等方面的知识。
通过这个案例,将获得以下收获:理解K均值聚类算法的逻辑,包括相似度度量、算法逻辑和算法评估等方面的知识。还将掌握应用聚类算法时涉及到的数据可视化、数据清洗、相关性分析和维度归约等操作。此外,还将学习K均值算法的调优策略以及在商业分析中的解释。
03 这门课谁适合学?
数据科学爱好者:通过学习K均值聚类算法,深入了解数据聚类的原理和应用,并在未来的数据分析项目中运用这些知识。
商业分析师:K均值聚类算法在客户画像、产品分群和精准营销等领域广泛应用,可以掌握如何利用聚类算法进行商业数据分析和决策。
数据分析师:学习K均值聚类算法,掌握数据可视化、数据清洗、相关性分析和维度归约等操作,进一步提高分析的准确性和效果。
IT专业人员:通过学习K均值聚类算法和项目中所涉及的数据清洗、调优流程,将这些技能应用到其他领域,如异常客户监测和个性化推荐等。
04 这门课学什么?这是一门商业数据挖掘案例课。一共1个章节,预计一周内的时间学完。
 部分案例截图:
部分案例截图:
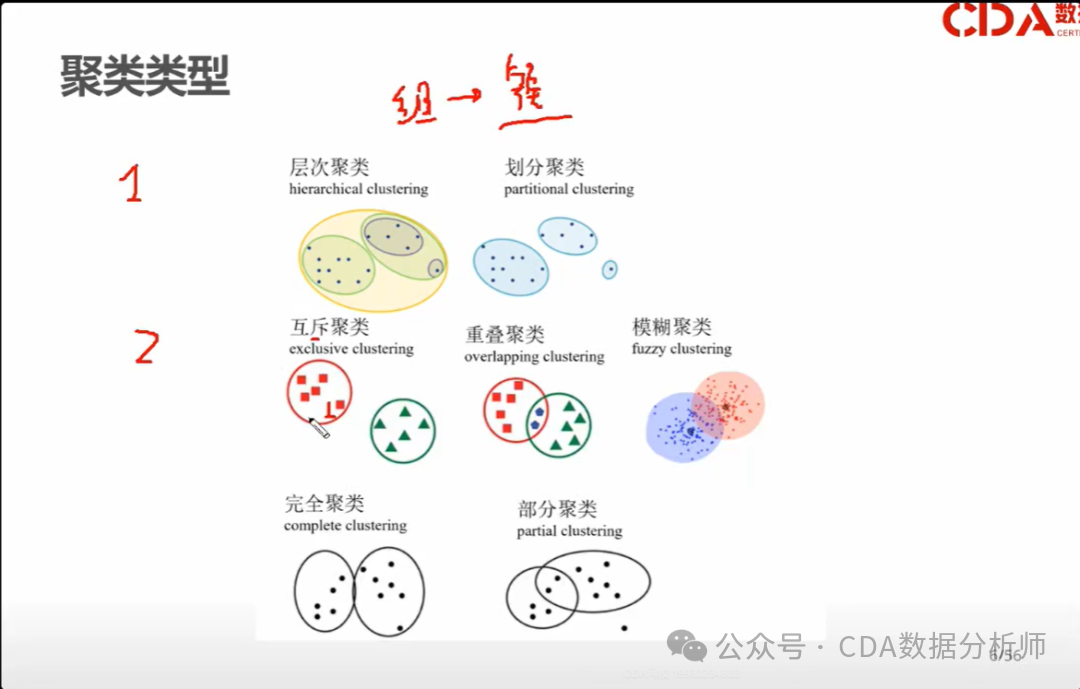

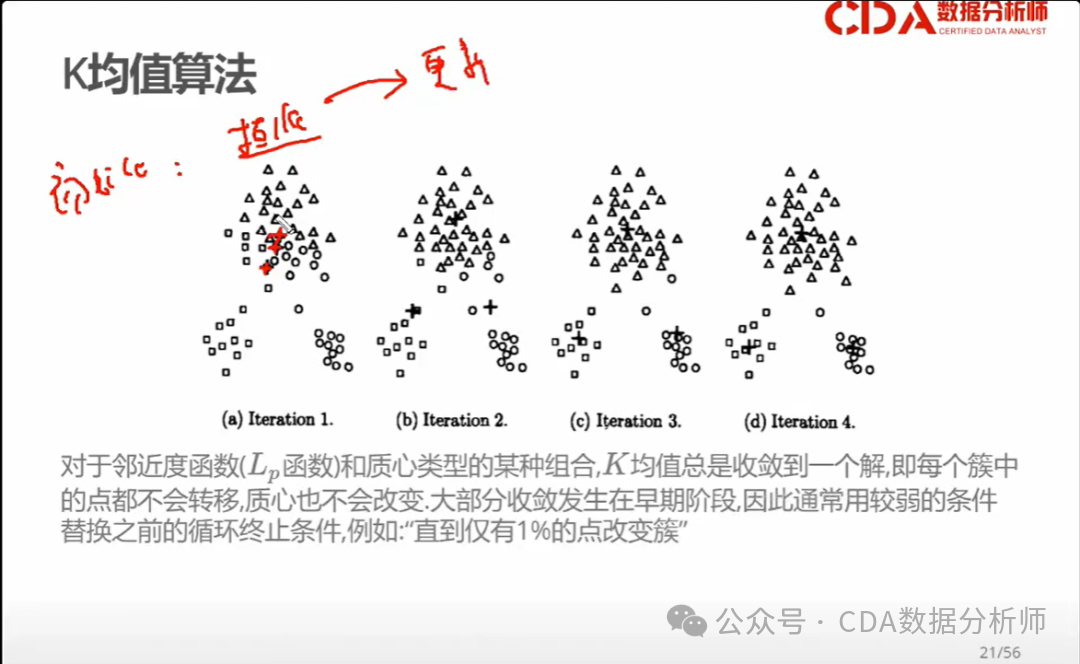

 在当今竞争激烈的市场环境中,了解客户需求并制定有效的策略对于企业的成功至关重要。
在当今竞争激烈的市场环境中,了解客户需求并制定有效的策略对于企业的成功至关重要。
从实际案例出发,利用一个通信运营商提供的接口,解析用户的定位数据和属性信息,并对基站进行分群,以选择适合的区域展开精准营销活动。深入了解K均值聚类算法的算法逻辑、相似度度量和评估方法等核心知识。
通过完整的案例学习,掌握应用聚类算法时所涉及的数据可视化、数据清洗、相关性分析和维度归约等操作技巧,还将了解K均值算法的调优策略和在商业分析中的解释。这些技能将提升在数据处理和分析领域的能力,并为在职场上获得更多机会铺平道路。
不要错过这个机会,购买我们的课程,与我们一起探索K均值聚类算法的奥秘,学习应用于实际场景的技巧,成为数据驱动的专家!立即行动,开启您的学习之旅吧!扫描二维码或者点击原文链接即可报名!
报名入口:https://edu.cda.cn/goods/show/958
查看更多课程:https://edu.cda.cn/course/explore/project_1
CDA数据分析师考试相关入口一览(建议收藏):
▷ 想报名CDA认证考试,点击>>>
“CDA报名”
了解CDA考试详情;
▷ 想学习CDA考试教材,点击>>> “CDA教材” 了解CDA考试教材;
▷ 想加入CDA考试题库,点击>>> “CDA题库” 了解CDA考试题库;
▷ 想了解CDA考试含金量,点击>>> “CDA含金量” 了解CDA考试详情;
▷ 想了解CDA院校合作,点击>>> “院校合作” 了解咨询CDA院校合作;












 京公网安备 11010802034615号
经营许可证编号:京B2-20210330
京公网安备 11010802034615号
经营许可证编号:京B2-20210330